It was a Friday afternoon at Gringo. We had just finished presenting three months of work to a group of stakeholders. The room was quiet in the wrong way.
One of the directors looked at the screen, paused, and said: "it's good, but I imagined something different."
There was nothing wrong with the execution. The team had delivered exactly what was agreed at the beginning. The problem was that "the beginning" had been months ago — and the business had moved on while the project stayed frozen in time.
I learned something that day that isn't in any agile framework: the biggest risk in a project isn't technical complexity. It's the silence between kickoff and delivery.
Slicing is not cutting scope
The first pushback you get when proposing smaller deliveries is: "but then it'll only be half done." That reaction is understandable, but it reveals a fundamental mistake.
There are two completely different things at play here.
Scope cut means removing functionality from the final product. You deliver less than you planned. It's a concession.
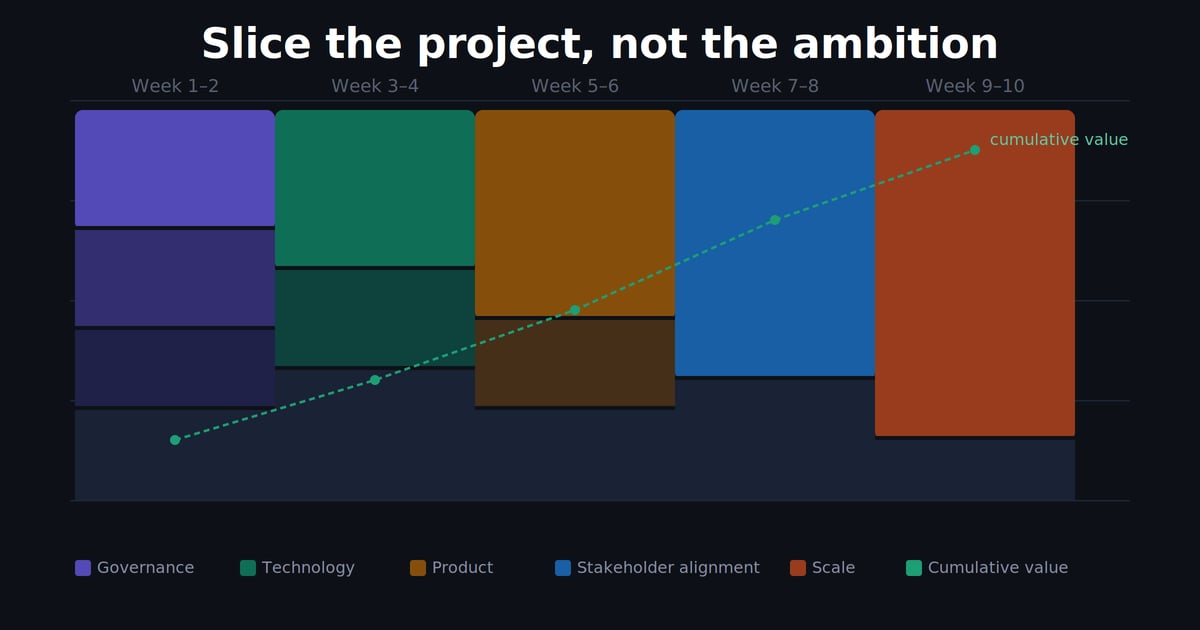
Value slice means delivering the smallest unit that can be independently verified and evaluated. You deliver the complete product in iterations — each with its own value, each with acceptance criteria defined before work begins.
The practical difference is enormous. In the second model, stakeholders don't wait months to see something. They see real progress every one or two weeks — and that changes the entire dynamic between those who build and those who decide.
The main benefit isn't delivery speed. It's continuous learning and a lower cost of changing course. When you discover something needs to change after two weeks, the damage is small. When you discover it after four months, it's catastrophic.
I've made both mistakes. The second one hurts more — and stays with you longer.
The four-step cycle
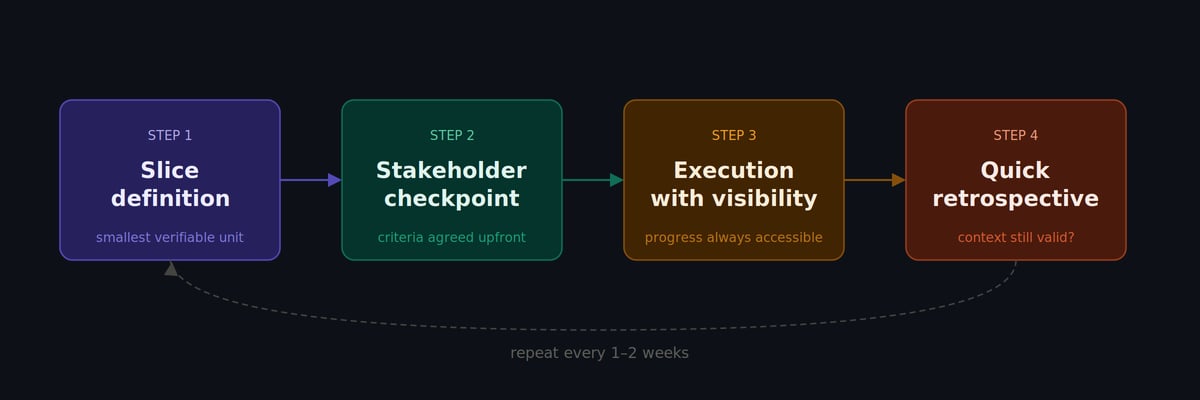
In practice, effective slicing works as a cycle repeated every one or two weeks:
1. Slice definition — what is the smallest deliverable with verifiable value? Not the smallest set of tasks, but the smallest delivery that someone can evaluate and say "this works" or "this isn't what we need."
2. Stakeholder checkpoint — acceptance criteria agreed before work starts, not after. This is the step most teams skip — and it's exactly where misalignment takes root. In my experience, when the acceptance criteria isn't written before work begins, it will be rewritten after delivery. And by then it's too late.
3. Execution with visibility — progress accessible throughout, not saved for the final demo. Stakeholders don't need to wait to know what's happening.
4. Quick retrospective — has the context changed? Does the next slice still make sense? This question, asked every cycle, prevents teams from continuing to execute a plan the business has already moved on from.
How AI fits into each step
Generative AI tools work best when context is clear and scope is small. That's exactly what slicing creates — and exactly how we used it at Gringo.
In definition, we used LLMs to break large epics into smaller units with acceptance criteria, prioritize by impact versus effort, and surface dependencies that weren't immediately obvious. A refinement session that would take two hours with the team became a 20-minute conversation with the model doing the heavy lifting on structure.
In stakeholder checkpoints, AI was particularly useful for translating technical progress into business language. We'd take the team's technical notes, run them through a model with instructions to calibrate for an executive audience, and have a summary ready for the meeting. Feedback improved because communication improved — not because the work changed.
In execution, code copilots, automated pull request reviews, and documentation generated along the way freed the team to think at a higher level. AI absorbed the repetitive work and made room for the work that requires judgment.
In retrospectives, analyzing patterns in historical data — past retros, recurring incidents, estimation drift — helped the team stop repeating the same mistakes due to lack of institutional memory.
The Gringo case
Gringo is Brazil's largest driver support platform, with over 20 million users. Much of the platform's experience depends on external data: vehicle documentation, driver's license scores, debt information, toll records — an ecosystem of APIs from dozens of different providers, consumed at scale.
When we set out to structure the governance of that consumption as a competitive advantage, the challenge became clear quickly: it was a three-dimensional problem. There was a governance dimension (who provides what, at what cost, with what quality), a technology dimension (how the application consumes that data, where the inefficiencies are, what can be optimized), and a product dimension (what the user is actually experiencing, where the journey breaks, where it can improve).
My first instinct was to build an integrated project that would solve all three dimensions in a coordinated way. Fortunately, I didn't follow that instinct.
Trying to solve all three dimensions at once would have stalled everything — each track has a different rhythm, vocabulary, and stakeholder. The solution was to run three parallel tracks in one-to-two-week slices, each with its own owner, acceptance criteria, and verifiable deliverable.
Governance track
Every cycle, one concrete deliverable visible to the business: consumption mapping, vendor consolidation, audit process, saving opportunity identification. Not one big report at the end — small, trackable advances, week by week, with the CFO following in real time.
Technology track
Progressive review of the application's consumption architecture, log analysis, bottleneck identification. From diagnosis, incremental implementation of strategies: caching, call orchestration, critical dependency mapping. Each improvement validated before moving to the next — no big refactors all at once.
Product track
This was the track that most needed a new vocabulary. Technical API metrics — latency, error rate, availability — didn't communicate the real impact on user experience in a way non-technical stakeholders could evaluate and act on.
I created two frameworks to solve this.

UTP — User Total Performance: measures the time in seconds from the user's request to the delivery of meaningful data to the application. Not the isolated API latency, but the total time the user experiences. A single, understandable number that any stakeholder can evaluate without needing to understand the underlying architecture.
UTF — User Total Failure: measures the percentage of users experiencing a problem at each stage of the journey. Instead of an aggregated technical error rate, visibility by stage — exactly where the experience breaks, for how many users, how often.
What changed with UTP and UTF wasn't just the metric — it was the conversation. Stakeholders stopped asking for technical reports and started asking: "what's the UTP today? Where's the highest UTF?" The infrastructure complexity stayed the same. Everyone's ability to understand and make decisions about it increased dramatically.
The results
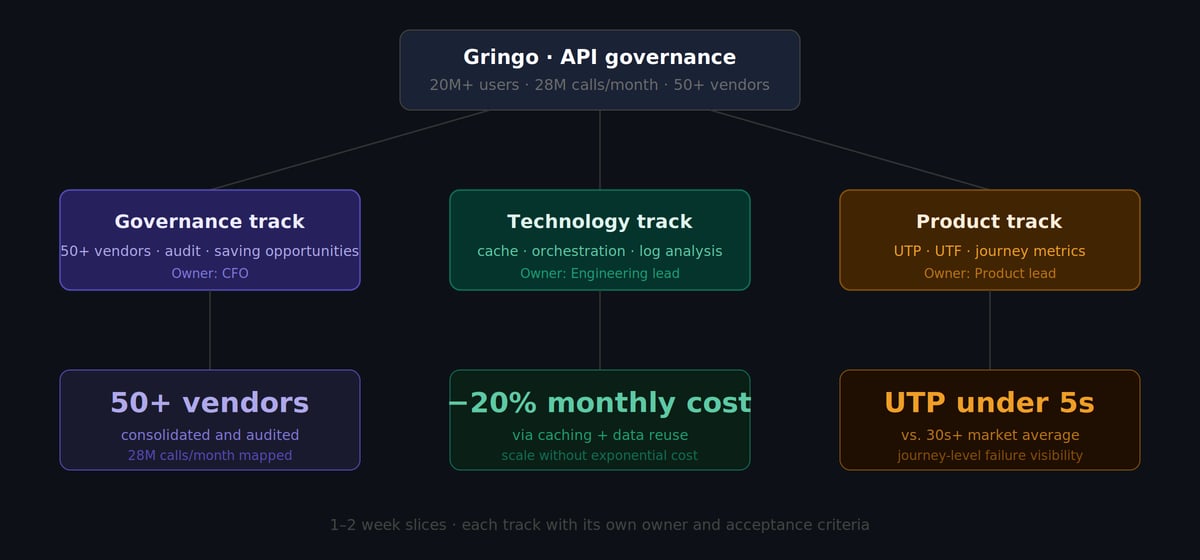
Months of work in one-to-two-week slices across three tracks produced results that would be hard to achieve in a monolithic project:
- 28 million API calls per month mapped, audited, and under structured governance
- 50+ vendors consolidated into a single management process
- 20% monthly cost reduction through caching and data reuse — scaling with cost reduction, not exponential invoice growth
- Onboarding with data delivered in under 5 seconds — in a context where 30+ seconds is common in the market
Every one of those results is traceable to specific slices, in specific tracks. There's no "project that delivered all this" — there's a sequence of small deliveries, each validated, that compounded.
Stakeholders aren't bureaucracy — they're part of the product
There's a frequent objection when someone proposes weekly stakeholder checkpoints: "that will consume the team's time and slow everything down."
It's a legitimate concern — and I heard it many times. The resistance usually comes from two different places.
The first is bad experience with unstructured meetings. If the checkpoint becomes a status meeting with no agenda and no decision, it's real overhead. The solution isn't to eliminate the checkpoint — it's to structure it. A concrete deliverable, pre-agreed acceptance criteria, 30 minutes with a decision at the end. That doesn't consume team time: it frees it.
The second is cultural. In organizations with heavy governance, stakeholders are used to approving, not co-building. Changing that pattern takes time and accumulated trust. My suggestion for anyone facing that barrier: start with one stakeholder who's already open to the process, show the result, and let the example spread. Imposing the model top-down rarely works.
When the checkpoint has structure, the dynamic shifts from "presenting for approval" to "co-building in public". The stakeholder stops being the judge of the final delivery and becomes part of the process. When they've seen progress every two weeks, there are no surprises at the end.
And the cost of change drops dramatically. Discovering that the direction is wrong after two weeks of work is an adjustment. Discovering it after four months is a disaster — technical, financial, and trust-wise.
The discipline of slicing is a competitive advantage
Teams that deliver in validated slices develop three advantages that compound over time.
First, they learn faster. Every cycle is an experiment with real feedback. The team's learning curve is steeper than those who only receive feedback at the end.
Second, they build trust with the business. Stakeholders who see consistent progress have more tolerance for uncertainty and more willingness to support difficult decisions. Trust is built with consistency, not with big promises.
Third, they use AI more effectively. Generative AI tools work best when context is clear, scope is bounded, and the task has a completion criterion. Well-defined slices create exactly that environment — every step of the cycle becomes a better prompt, a more precise review, a more useful document.
There's a fourth advantage that takes longer to appear, but is the most valuable: you stop fearing course corrections. When the cycle is short, redirecting isn't failure — it's part of the process. Teams that understand this operate with a different kind of ease. Not because they work less, but because the work has verified direction.
What's the smallest slice you can define, deliver, and validate this week?
Not the entire project. Not the next full sprint. The smallest unit with verifiable value — the one that, by the end of the week, someone can look at and say: "this works" or "it needs to change."
If you're stuck in a large project right now, here's my practical suggestion: take the current scope, list the parts that could be evaluated independently, and pick the riskiest one. Start there. The biggest risk usually reveals problems earliest — and it's better to know early.
If you want to talk through how to apply this in your team or company's context, I'm on MentorCruise and LinkedIn. A good part of the conversations I have with founders and product leaders goes through exactly this kind of challenge.
Victor Barros is an entrepreneur, investor, and board member with 17+ years of experience in product, technology, and governance. Founder of Eskolare and former partner and GM at Gringo (acquired by Corpay in 2025).






