I believe that implementing a standard process model should be the Data Science norm, not the exception.
CRISP-DM for Data Science
I've been using CRISP-DM (Cross Industry Standard Practice for Data Mining) as a process model for my Data Science project execution work for a few years and I can confirm that it works.
The process consists of 6 major steps and all the Data Science sub-tasks can be mapped as below:
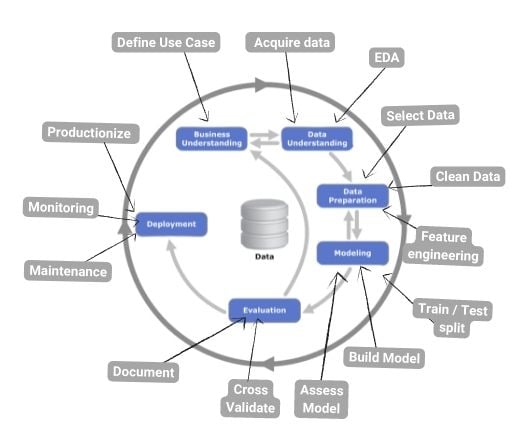
Data Science Lifecycle
While studying for the DELL EMC Data Science Associate Exam, I learned that DELL also recommends a Data Science lifecycle. In the course, the Data Science lifecycle is also divided into 6 phases, named differently, but having the same functions: Discovery - Data Prep - Model Planning - Model Building - Communicate Results - Operationalize.
The Data Science lifecycle it's an iterative process; you'll move through the phases if sufficient information is available.

1. Business Understanding
- Determine business objectives and goals
- Assess situation
- Produce project plan
It might seem like you need to do a lot of documentation even from the initial phase (and this is considered one of the few weaknesses of CRISP-DM), but a formal one-pager with the signed-off Business Case, that clearly states both business and machine learning objectives, along with listing the past information related to similar efforts should be documented. This exercise will prioritize items in your backlog and protect you from scope creep.

Pic. Source: The Machine Learning Project Checklist
2. Data Understanding
- Collect initial data
- Describe data
- Explore data
- Verify data quality
This is the "scary", time-consuming and crucial phase. I would sum it up as ETL/ELT + EDA = ♥
Acquiring data can be complex when it originates from both internal and external sources, in a structured and unstructured format, and without the help of a Data Engineer (they are so Rare Unicorns nowadays). Without having good quality data, Machine Learning projects will become useless. This part is missing in most online Data Science courses/competitions, so Data Scientists should learn how to do ETL/ELT by themselves.
EDA (Explanatory Data Analysis) got simple as this can be automatically performed with packages like pandas profiling, sweet viz, Dtale, autoviz in Python or DataExplorer, GGally, Smarteda, and tableone in R. Some teams will use a mix of automated and custom EDA features.
Data Preparation
- Select data
- Clean data
- Construct data
- Integrate data
- Format data
This is another code-intensive phase and it means knowing your dataset in great detail so it gives you the confidence to select data for modeling, clean it and perform feature engineering. The EDA stage will tell you if you have missing data, outliers, highly correlated features, and so on, but in the Data Prep stage, you have to decide what imputation strategy to apply. You might go back to Business Understanding in case you form a new hypothesis or you require confirmations from Subject Matter Experts.
Featuring engineering is a hot topic here. Until recently, this was a tedious task, mostly manual that involved creating new variables based on available features using data wrangling techniques. Data Scientists will use pandas in python and dplyr in R. Nowadays, frameworks like Featuretools will save the day. I wouldn't rely 100% on an automated feature engineering tool, but overall, it's a nice addition to a Data Science project.
Feature selection
- Feature importance: some algorithms like random forests or XGBoost allow you to determine which features were the most “important” in predicting the target variable’s value. By quickly creating one of these models and conducting feature importance, you’ll get an understanding of which variables are more useful than others.
- Dimensionality reduction: One of the most common dimensionality reduction techniques, Principal Component Analysis (PCA) takes a large number of features and uses linear algebra to reduce them to fewer features.
By the end of this phase, you've 70% - 80% completed the project. But the fun begins in the next phase:
Modeling
- Select modeling techniques
- Generate test design
- Build model
- Assess model
Once it is clear which algorithm to try (or try first), you'll have to:
from sklearn.model_selection import train_test_split .
Splitting your dataset into train and test is key for building a performant model. You'll build the model on the trained dataset (usually consisting of 70% of your data) and check how it performed on the test dataset (30% of data).
Don't forget to: random_state / seed
This code will help you reproduce the same random split result.
Based on the complexity of the model, building the code can be as quick as writing 2 lines of code. For Python scikit-learn is your model building library. In R you have packages like the caret, e1071, xgboost, randomForest, etc.
While assessing the accuracy of your model, you might decide to go back to the previous step/s and reiterate. Time spent on modeling is subjective as models can be improved with more tuning, but if time is more valuable than the % increase in accuracy, you'll want to move to the next step.
Some rule of thumb in modeling is that you shortlist the models that have at least 70% accuracy for unsupervised and 80% for supervised. You should also look at the loss function, setting up the threshold, accuracy matrix, and sensitivity/specificity.
Evaluation
- Evaluate results
- Review process
- Determine the next steps
At this step, you'll have to decide which model to select using tools like ROC Curves, the number of features, and also business feedback.
You can find more reading on this topic here:: I linked this blog as it's written by a Data Scientist, with hands-on experience.
Deployment
- Plan deployment
- Plan monitoring and maintenance
- Produce final report
- Review project
While preparing for deployment, you should create a final report and document if the model met objectives, start monitoring model stability, and accuracy and when retrain should be triggered.
Also, always communicate back to business.
MLOps Lifecycle
You probably noticed that I use the "automated" term several times across the article. Does this mean that Machine Learning can be 100% automated and that Data Scientists will not be in demand in the future? Well, I believe quite the contrary, junior Data Scientists will be enabled to ramp on very quickly using tools like:
- DataRobot
- H2O
- Alteryx
- RapidMiner
- Dataiku DSS
- Amazon SageMaker
- Google Cloud AutoML
- Qlik AutoML
- Azure Machine Learning Studio
If you want to read more on this, visit my blog:
https://thebabydatascientist.com/the-handbook-of-data-science-and-mlops/






