What is Dynamo?
Dynamo is highly available data storage technology that has a simple key/value interface, is highly available with a clearly defined consistency window, is efficient in its resource usage, and has a simple scale out scheme to address growth in data set size or request rates.
Why was it built?
Dynamo was built to address the requirement of building an highly available shopping cart for Amazon, which allows the customers to always add items to a cart. It is a very important property of that cart since an unavailable cart means a loss in order of magnitudes for Amazon due to drop in orders and a very bad customer experience.
The paper tries to pin point the fact that in those days everything was stored in RDMS ( Oracle ) databases which are painful to maintain for higher availability and scalability. Also, a shopping cart application do not need a full fledged RDMS solution as they do not need to perform any rich queries on that database. What they needed was a simple data store with a simple query model which is highly available always allowing customers to use their cart.
Highly Available and eventually consistent
Dynamo chose ‘A’ (as in availability) from the CAP theorem as required by their business use-case. It means, it chose to be highly available by using optimistic replication techniques where the changes are pushed to the replicas in background resulting in eventual consistent data storage; that is all updates reach all replicas eventually. This however can lead to conflicting changes which must be detected and resolved.
When and who performs conflict resolution
Since Dynamo targets an ‘always writeable’ data storage, it does wants to have the conflict resolution during reads hence allowing writes to never get rejected. If the conflict resolution was done during writes, it could be possible that some writes may be rejected if the data store cannot reach all (or a majority of) the replicas at a given time.
The next design choice is who performs these conflict resolutions — data store or the application. If it is datastore, then it’s choices are limited where it can use simple policies like “last write wins”. However, if it is the application, then since it is aware of the data schema it can make better decision suited best for the customer experience.
Incremental scalability
The system should be able to scale one host/machine at a time with minimal impact on the availability.
Symmetry and Decentralization
There should be no special nodes in Dynamo with no centralized controllers or leaders. Every node performs the same responsibilities as its peers.
Heterogeneity
The system should run smoothly with a heterogenous fleet of the servers.
System Architecture
The Dynamo architecture can be summarized as:
A replicated DHT with consistency management using
- Consistent hashing (partitoning)
- Optimistic Replication
- Sloppy quorum (for handling temporary failures)
- Anti-entropy mechanisms (for handling permanent failures)
- Object versioning (for high availability during writes)
Partitioning
As noted above, one of the key requirements of Dynamo is to scale incrementally which requires a mechanism to dynamically partition the data over the set of nodes. For this, it uses consistent hashing where the output range of the hash functional is treated as fixed circular ring (the largest hash value wraps to the smallest value).
Each node in the system is assigned a random position on the ring such that it owns the hash region between itself and its predecessor.
Dynamo however adds a variation to the consistent hashing by having a concept ‘virtual’ nodes where each node gets assigned multiple points on the ring instead of just one. This allows the system to get away with problem of non-uniform data and load distribution that can happen with assigning just one random location.
Replication
To ensure high availability, Dynamo replicates each data item on multiple (N) hosts/nodes in the system. Each key is assigned to a coordinator node (the node that first falls in the range) which first stores the data locally and then replicates it to N-1 clockwise successor nodes on the ring. This results in each node owning the region on the ring between it and its Nth predecessor. The list of nodes responsible for storing a data item is called the preference list.
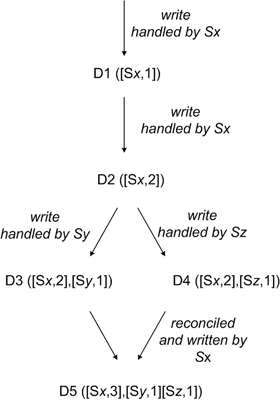
Data versioning
Dynamo provides eventual consistency where the data is propagated asynchronously to all its replicas. Since a put request may return even before the data has been stored in all its replicas, a get may return multiple versions of the data.
To provide high availability, Dynamo chose the version reconciliation during read rather than on write as it always wants the data to get written. It uses vector clocks to capture causality between different versions of the same object. From the paper,
“A vector clock is effectively a list of (node, counter) pairs.One vector clock is associated with every version of every object. One can determine whether two versions of an object are on parallel branches or have a causal ordering, by examine their vector clocks. If the counters on the first object’s clock are less-than-or-equal to all of the nodes in the second clock, then the first is an ancestor of the second and can be forgotten. Otherwise, the two changes are considered to be in conflict and require reconciliation."
Execution of get() and put() operations
In Dynamo, any node in the fleet is eligible to receive get() or put() request for any key which will happen especially when the fleet is behind a load balancer. A node handling the read/write operation for a given key is known as coordinator. For a node to act as coordinator, it must be part of the preference list (N nodes) for the given key. However, in case a node receives a request for a key for which it is not in the preference list, it will route the request to the first among top N nodes in the preference list.
Dynamo uses a consistency protocol similar to used in quorum systems to maintain consistency among its replicas. It has two key configurable values: R, minimum number of nodes that should participate in successful read and W, minimum number of nodes that should participate in successful write operation. Setting these R and W will define how Dynamo will work. For example,
N = 1, R = 1, W =1 results in a distributed cache system where you get lowest latencies for read and write but lesser consistency.
N = 3, R = 2, W = 2 results in consistent and durable data store.
N = n, R = 1, W = n results high performance read engine
It can be seen that setting R + W > N will result in a quorum like system (typical configuration). However, the latency of put() or get() operation is then dictated by the slowest among W or R hosts so its better to keep values of R and W less than N.
For a put() request, the coordinator node first creates a new vector clock and uses that to store the data locally. It then forwards the new version along with the new vector clock to N highest ranked nodes skipping the unhealthy ones.
For a get() request, the coordinator requests all the existing versions of data for the key and then waits for R responses before returning the result to the client. If it receives multiple versions that are causally unrelated then it send back all those versions which will then be reconciled by client.






