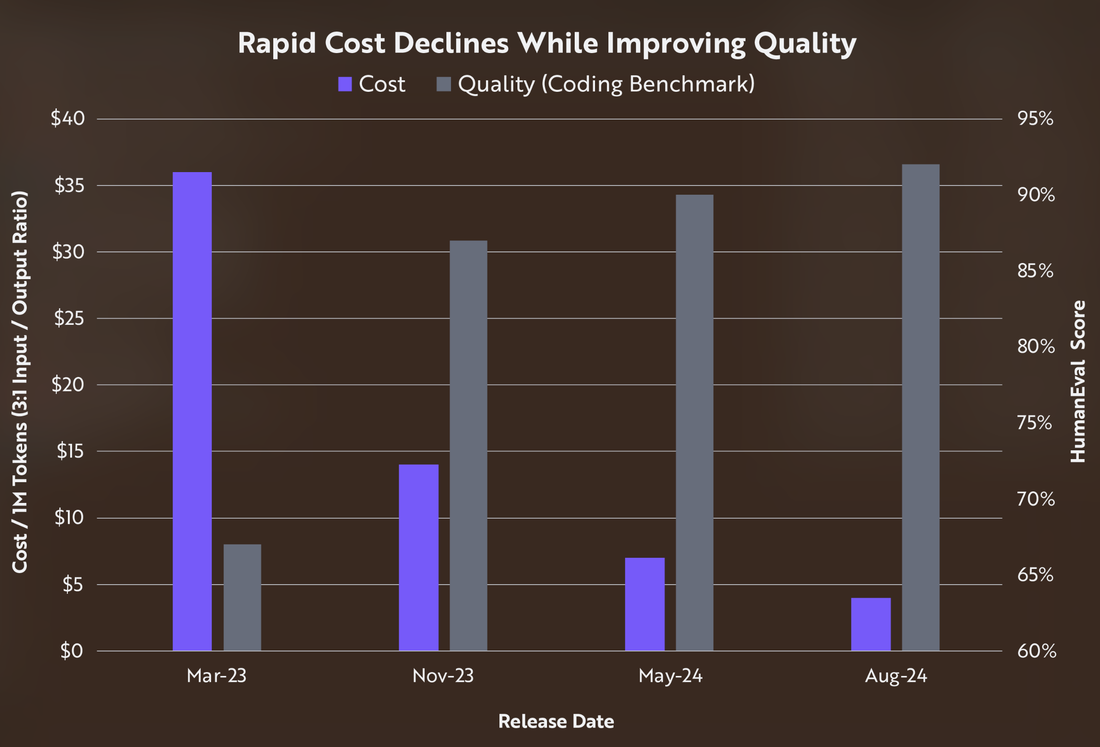
This image illustrates a significant trend in OpenAI's innovative work on large language models: the simultaneous reduction in costs and improvement in quality over time. This trend is crucial for AI product and business leaders to understand as it impacts strategic decision-making and competitive positioning. Key Insights:
- Cost Efficiency: The cost per million tokens has decreased dramatically by ~10x from ~$36 in March 2023 to about ~$3.5 by August 2024. This suggests technological advancements and increased efficiency in AI model training and deployment, making AI solutions more accessible and scalable.
- Quality Enhancement: The HumanEval scores, which measure coding benchmark quality, have improved from around 67% to over 92% during the same period, representing an improvement of ~33%. The benchmark consists of 164 hand-crafted programming challenges, each including a function signature, docstring, body, and several unit tests, averaging 7.7 tests per problem. These challenges assess a model's understanding of language, algorithms, and simple mathematics, and are comparable to simple software interview questions. This indicates that AI models are not only becoming cheaper but also more capable and reliable.
- Strategic Implications: For businesses, this dual trend of decreasing costs and increasing quality means that AI can be integrated into more applications with better performance outcomes. It allows companies to innovate more rapidly and offer enhanced products or services at lower costs, potentially leading to increased market share.
- Competitive Advantage: Organizations that leverage these advancements can gain a significant edge by delivering superior value to customers. The ability to provide high-quality AI-driven solutions at reduced costs can differentiate a company in a crowded market.
1. Cost-Effective Solutions:
- Affordable Access: By leveraging reduced operational costs, startups can offer competitive pricing, making advanced AI solutions accessible to a broader range of businesses.
- Scalability: Lower costs enable startups to scale their operations more efficiently, allowing them to serve larger markets or expand into new ones without prohibitive expenses.
2. Enhanced Product Offerings:
- Quality Improvement: With improved quality scores, startups can deliver more reliable and effective AI models, enhancing customer satisfaction and trust.
- Innovation: The ability to offer high-quality outputs at lower costs allows startups to innovate and experiment with new applications, potentially leading to unique product offerings that differentiate them in the market.
3. Strategic Investment in R&D:
- Focus on Customization: Startups can invest in developing tailored solutions that meet specific customer needs, using generative AI's capabilities for personalization and customization
- Continuous Improvement: By reinvesting savings from reduced costs into research and development, startups can maintain a competitive edge through continuous product enhancements.
4. Operational Efficiency:
- Automation and Optimization: Generative AI can automate routine tasks, optimizing business processes and freeing up resources for higher-value activities
- Resource Allocation: Efficient cost management allows startups to allocate resources strategically, focusing on areas that maximize impact and profitability
5. Key Trade-offs
Hosting Costs
Self-hosting large models can cost upwards of $27,360 per month for 24/7 operation on high-performance infrastructure like AWS ml.p4d.24xlarge instances.
Speed vs Quality
Parallelizing LLM queries can improve speed and accuracy but leads to increased costs and potential content duplication.
Optimization Strategies
- Model Selection: Choose models based on task complexity - use more expensive models only for complex tasks requiring higher accuracy.
- Quantization: Implementing model quantization can significantly reduce hosting costs and improve latency while maintaining acceptable accuracy levels.
- Hybrid Approach: Using different models for different tasks can optimize costs - simpler tasks can use less expensive models while complex tasks use advanced models.
6. Cost of self-hosting LLMs
Infrastructure Costs
Hardware Requirements
- GPU servers can cost up to $38 per hour for AWS ml.p4d.24xlarge instances
- Running 24/7 operations can amount to approximately $27,360 per month
- Basic GPU setups like g5.2xLarge cost about $872.40 per month
Resource Components
- vCPUs: Approximately $1.61 per core monthly
- Memory: Around $2.56 per GB monthly
- Storage: About $0.09 per GB monthly
- GPU (NVIDIA A100): $1,219.94 per unit monthly
Operational Expenses
Model Size Impact
- Larger models require more computational resources
- 70B parameter model needs approximately 280GB storage at 32-bit precision
- Quantization can reduce storage needs to around 70GB
Token Processing
- GPT-4: $0.03 per 1,000 input tokens, $0.06 per 1,000 output tokens
- GPT-3.5 Turbo: $0.0015 per 1,000 input tokens, $0.002 per 1,000 output tokens
Additional Costs
Maintenance Requirements
- IT infrastructure for model retraining
- Specialized team expertise
- Regular updates and optimization
- Additional costs for RAG frameworks and vector store
7. Strategies to balance performance vs. cost
Smart model selection
- Use smaller models for simple tasks like classification or basic Q&A
- Reserve larger, more expensive models for complex tasks requiring deeper understanding
- Implement hybrid workflows combining different model sizes for optimal cost-efficiency
Caching Strategies
- Implement exact caching for identical inputs
- Use fuzzy caching for similar queries
- Store responses to prevent redundant processing
LLM caching results in:
Reduced Latency
- Faster response times by eliminating redundant computations
- Quick retrieval of cached responses instead of generating new ones
- Up to 84% decrease in retrieval times through semantic caching
Computational Efficiency
- Lower computational overhead by avoiding repeated processing
- Reduced number of API calls to LLM services
- Optimized resource utilization through stored intermediate computations
Token Management
- Optimize prompts to reduce token usage
- Implement early stopping to prevent unnecessary token generation
- Use prompt compression techniques
Batching and Routing
- Group multiple requests together for efficient processing
- Implement intelligent request routing based on task complexity
- Use model quantization to reduce resource requirements
Performance Monitoring
- Track usage patterns and costs regularly
- Identify high-cost areas in applications
- Implement robust usage tracking systems
8. Monitoring Costs
You can use a variety of solutions to monitor your LLM costs:
LangSmith
- Provides comprehensive logging of LLM activities and token usage
- Offers detailed cost tracking and optimization tools
- Integrates seamlessly with LangChain framework2
Helicone
- Open-source platform with Y Combinator backing
- Features caching and rate limiting for cost savings
- Offers generous free tier of 50K monthly logs17
Datadog
- Provides end-to-end tracing for LLM workflows
- Tracks operational metrics and token usage costs
- Offers detailed cost breakdowns by model and application110
Cost Analysis
- Token usage tracking
- Real-time cost monitoring
- Expense forecasting and budgeting tools
Performance Optimization
- Caching mechanisms
- Rate limiting capabilities
- Resource utilization tracking
Visualization
- Cost breakdown dashboards
- Usage pattern analysis
- Performance metrics visualization
Token Tracking
- Input/output token consumption
- Cost per model analysis
- Usage pattern identification10
Budget Management
- Real-time spend monitoring
- Cost allocation tracking
- Budget alert systems
9. Conclusions
The key is finding the right balance between cost and quality based on specific use case requirements and budget constraints. By strategically leveraging these advantages, generative AI startups can enhance their value proposition, attract more customers, and establish a strong foothold in the rapidly evolving AI landscape. Overall, these strategies enable startups to deliver high-quality, innovative solutions at lower costs, providing substantial value to their customers while securing a competitive edge in the market.






