✍ In this blog, I present a detailed analysis of the Mixtral model architecture and the specialized attention mechanisms that endow it with superior capabilities vs. other large language models that have up to ~5x more active parameters like Meta's LLaMA-2. To read the full blog, visit - https://sundeepteki.org/mixtral-of-experts
Introduction
Mistral is a pioneering French AI startup that launched their own foundational large language model, called Mistral 7B in September 2023. As of the date of launch, it was the best 7 billion parameter language model, outperforming even larger language models like Llama 2 of size 13 billion parameters across multiple benchmarks. In addition to its performance, Mistral 7B is also popular as the model is open-sourced under the Apache 2.0 license with the model weights available for download.Mixtral 8x7B (hereafter, referred to as “Mixtral”) is the latest model released by Mistral in January 2024 and represents a significant extension of their prior work on Mistral 7B. It is a 7B Sparse Mixture of Experts (SMoE) language model with stronger capabilities than Mistral 7B. It uses 13B active parameters during inference out of a total of 47B parameters, and supports multiple languages, code, and 32k context window.In this blog, you will learn about the details of the Mixtral language model architecture, its performance on various standard benchmarks vis-a-vis state-of-the-art large language models like Llama 1 and 2 and GPT3.5, as well as potential use cases and applications.
1. Introduction
Mistral is a pioneering French AI startup that launched their own foundational large language model, called Mistral 7B in September 2023. As of the date of launch, it was the best 7 billion parameter language model, outperforming even larger language models like Llama 2 of size 13 billion parameters across multiple benchmarks. In addition to its performance, Mistral 7B is also popular as the model is open-sourced under the Apache 2.0 license with the model weights available for download.Mixtral 8x7B (hereafter, referred to as “Mixtral”) is the latest model released by Mistral in January 2024 and represents a significant extension of their prior work on Mistral 7B. It is a 7B Sparse Mixture of Experts (SMoE) language model with stronger capabilities than Mistral 7B. It uses 13B active parameters during inference out of a total of 47B parameters, and supports multiple languages, code, and 32k context window.In this blog, you will learn about the details of the Mixtral language model architecture, its performance on various standard benchmarks vis-a-vis state-of-the-art large language models like Llama 1 and 2 and GPT3.5, as well as potential use cases and applications.
2. Mixtral
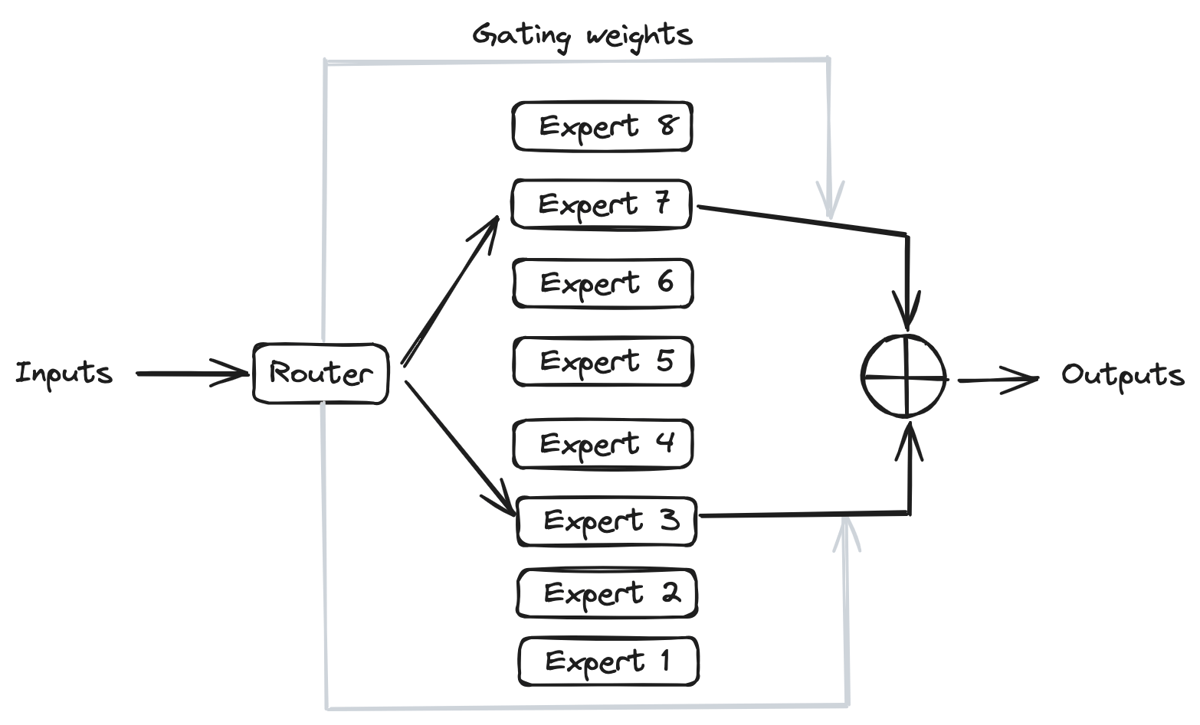
Mixtral is a mixture-of-experts network, similar to [GPT4]. While GPT4 is said to constitute 8 expert models of 222B parameters each, Mixtral is a mixture of 8 experts of 7B parameters each. Thus, Mixtral only requires a subset of the total parameters during decoding, thus allowing faster inference speed at low batch sizes and higher throughput at large batch sizes. 2.1 Sparse Mixture of ExpertsFigure 1 illustrates the Mixture of Experts (MoE) layer. Mixtral has 8 experts, and each input token is routed to two experts with different sets of weights. The final output is a weighted sum of the outputs of the expert networks, where the weights are determined by the output of the gating network. The number of experts (n) and the top K experts are hyperparameters that are set to 8 and 2 respectively. The number of experts, n determines the total or sparse parameter count while K determines the number of active parameters used for processing each input token.The MoE layer is applied independently per input token in lieu of the feed-forward sub-block of the original Transformer architecture. Each MoE layer can be run independently on a single GPU using a model parallelism distributed training strategy.2.2 Mistral 7BMixtral’s core architecture is similar to Mistral 7B, and therefore, a review of its architecture is relevant for a more comprehensive understanding of Mixtral. Mistral 7B is based on the Transformer architecture. In comparison to Llama, it has a few novel features that contribute to it surpassing Llama 2 (13B) on various benchmarks.

2.2.1 Grouped-Query Attention
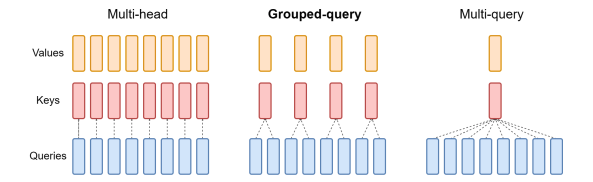
Grouped-Query Attention (GQA) is an extension of multi-query attention, which uses multiple query heads but single key and value heads. Popular language models like PaLM employ multi-query attention. GQA represents an interpolation between multi-head and multi-query attention with single key and value heads per subgroup of query heads. As shown in figure 2, GQA divides query heads into G groups, each of which shares a single key and query head. It is different to multi-query attention which shares single key and value heads across all query heads. GQA is an important feature as it significantly accelerates the speed of inference and also reduces the memory requirements during decoding. This enables the models to scale to higher batch sizes and higher throughput, which is a critical requirement for real-time AI applications.
2.2.2 Sliding Window Attention
Sliding window attention (SQA), introduced in the Longformer architecture exploits the stacked layers of a Transformer to attend to information beyond the typical window size. SWA is designed to attend to a much longer sequence of tokens than vanilla attention, and also offers significant reductions in computational cost.The combination of GQA and SWA collectively enhance the performance of Mistral 7B and therefore Mixtral relative to other language models like the Llama series.
3. Performance
3.1 Standard benchmarks
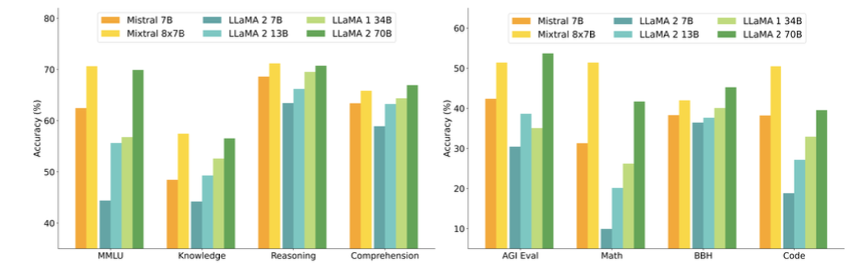
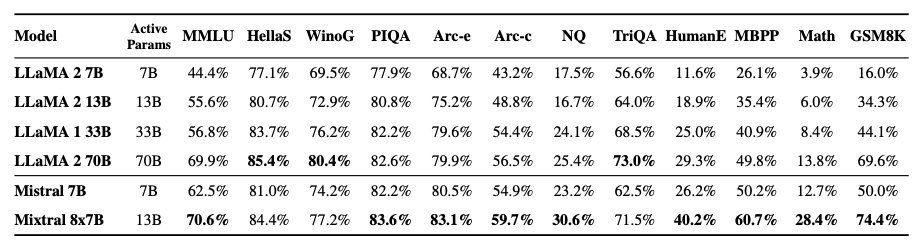
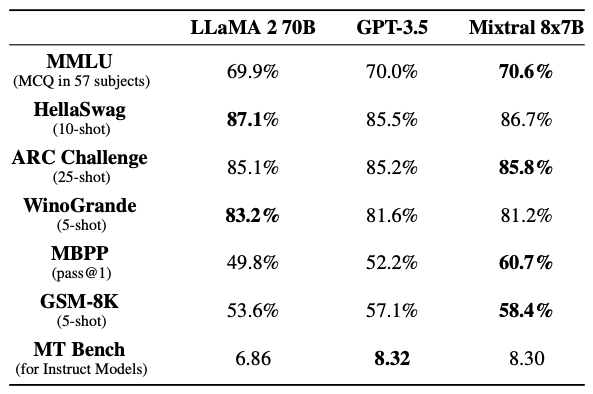
The authors of Mixtral benchmarked the performance of the model on a range of standard benchmarks and evaluated the accuracy of Mixtral versus leading language models like Llama 1, Llama 2, and GPT3.5 as shown in figure 3, table 1, and table 2.In summary, Mixtral is better than much larger language models with up to 70B parameters like Llama 2 70B while only using 13B (~18.5%) of the active parameters during inference. Mixtral’s performance is especially superior in tasks focused on mathematics, code generation, as well as multilingual comprehension.
3.2 Multilingual understanding
Table 3 shows the performance of Mixtral versus Llama models on multilingual benchmarks. As Mixtral was pretrained with a significantly higher proportion of multilingual data, it is able to outperform Llama 2 70B on multilingual tasks in French, German, Spanish, and Italian while being comparable in English.
3.3 Long-range performance
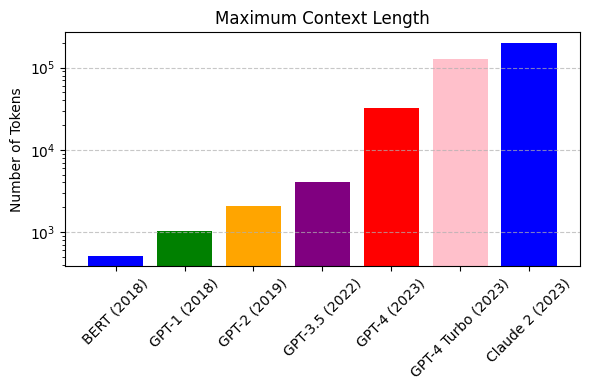
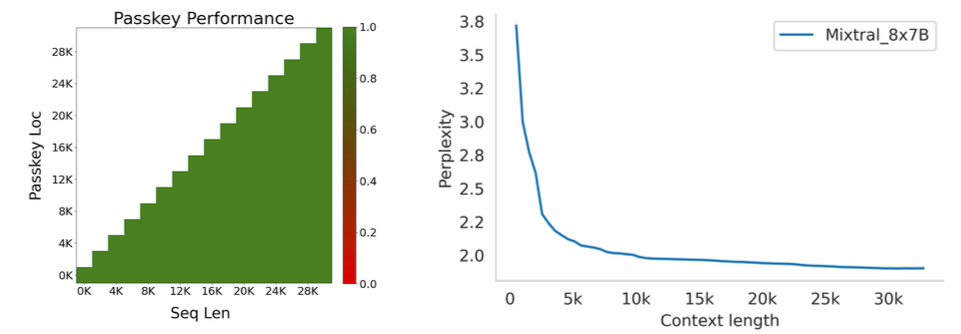
As shown in figure 4, the input context length of language models has increased by several orders of magnitude in the last few years - from 512 tokens for the BERT model to 200k tokens for Claude 2. However, most large language models struggle to efficiently use the longer context. Nelson and colleagues showed that current language models do not robustly make use of information in long input contexts, and their performance is typically highest when the relevant information for tasks such as question-answering or key-value retrieval occurs at the beginning or the end of the input context, with significantly degraded performance when the the models need to access information in the middle of long contexts.Mixtral, which has a context size of 32k tokens, overcomes this deficit of large language models and shows 100% retrieval accuracy regardless of the context length or the position of the key to be retrieved in a long context.The perplexity, a metric that captures the capability of a language model to predict the next word given the context, decreases monotonically as the context length increases. Lower perplexity implies higher accuracy, and the Mixtral model is therefore capable of extremely good performance on tasks based on long context lengths as shown in figure 5.
4. Instruction Fine-tuning
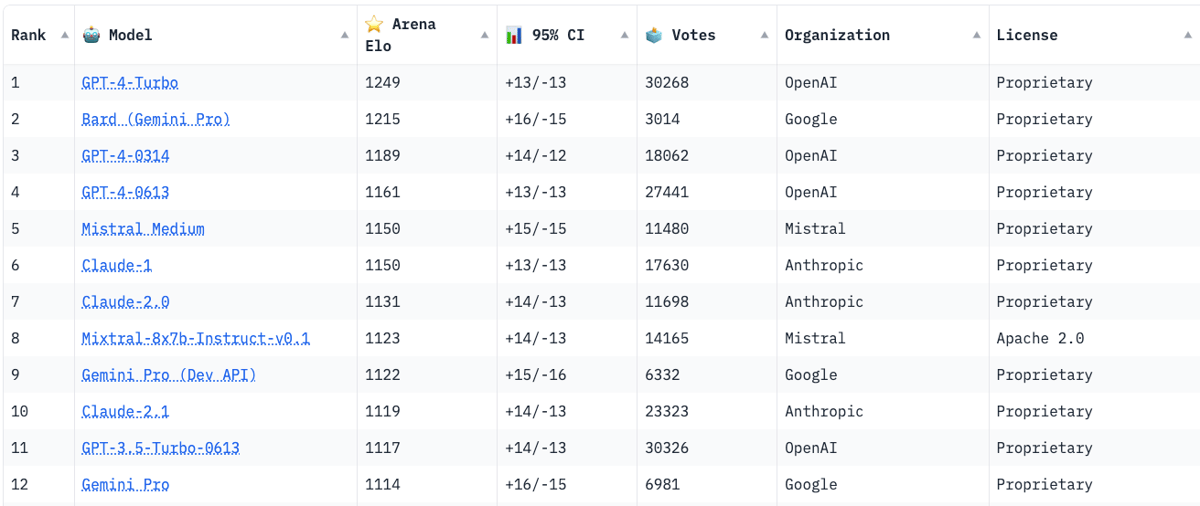
Instruction tuning refers to the process of further training large language models on a curated dataset containing (instruction, output) pairs of training samples. Instruction tuning is a computationally efficient method for extending the capabilities of large language models in diverse domains without extensive retraining or architectural changes. “Mixtral - Instruct” model was fine-tuned on an instruction dataset followed by Direct Preference Optimization (DPO) on a paired feedback dataset. DPO is a technique to optimize large language models to adhere to human preferences without explicit reward modeling or reinforcement learning. As of January 26, 2024, on the standard LMSys Leaderboard, Mixtral - Instruct continues to be the best performing open-source large language model. This leaderboard is a crowdsourced open platform for evaluating large language models that ranks models following the Elo ranking system in chess. Mixtral - Instruct only ranks below proprietary models like OpenAI’s GPT-4, Google’s Bard and Anthropic’s Claude models, while being a significantly small model.This extremely strong performance of Mixtral - Instruct and with an open-source friendly Apache 2.0 license opens up the possibility for tremendous adoption of Mixtral for both commercial and non-commercial applications. It represents a much more powerful alternative to Llama 2 70B that is already being used as the foundational model for extending large language models to other languages like Hindi or Tamil that are spoken widely but not adequately represented in the training dataset of these large language models.
5. Use Cases
Mixtral represents the numero uno of open-source large language models as it clearly outperforms the previous best open-source model, Llama 2 70B, by a significant margin, while providing for faster and cheaper inference. At the time of writing this article, Mixtral has been available in the open-source for less than two months and we are yet to see many examples of how it is being used in the industry. However, there are some early movers, like the Brave browser that has already incorporated Mixtral in its AI-based browser assistant, Leo. Mixtral is also incorporated by Brave for powering its [programming-related queries in Brave Search. It is only a matter of time before Mixtral witnesses widespread adoption across industry for a variety of use cases and challenges the hegemony of proprietary models like OpenAI’s GPT-4 and the likes.
6. Conclusion
Mixtral is a cutting-edge, mixture-of-experts model with state-of-the-art performance among open-source models. It consistently outperforms Llama 2 70B on a variety of benchmarks while having 5x fewer active parameters during inference. It thus allows for a faster, more accurate and cost-effective performance for diverse tasks including mathematics, code generation, as well as multilingual understanding. Mixtral - Instruct also outperforms proprietary models such as Gemini-Pro, Claude-2.1, GPT-3.5 Turbo on human evaluation benchmarks.Mixtral thus represents a powerful alternative to the much larger and more compute intensive Llama 2 70B as the de facto best open-source model, and will facilitate development of new methods and applications benefitting a wide variety of domains and industries.






