This can be achieved by taking the different regions of interest from an image and applying a classifier to classify the presence of an object within that region. The one main challenge is selecting a huge number of regions of interest from an image which could be computationally high!
Types of object detectors
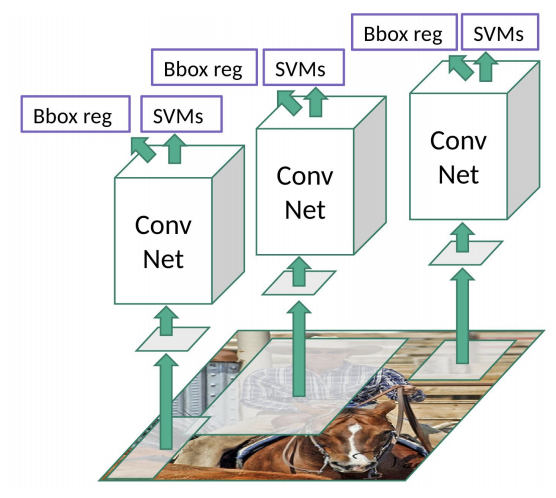
R-CNN
This proposed a concept called “Regional proposals”, uses a selective search method that extracts just 2000 regions from an image. Therefore, now, instead of trying to classify a huge number of regions, these regional proposals can be used.
The CNN, feature extractor that outputs dense layers consisting of features extracted from the image and that is fed into SVM to classify the presence of an object within that region proposal.
Spatial Pyramid Pooling(SPP-net)
RCNN was very slow. Because running CNN on 2000 region proposals generated by Selective search takes a lot of time. SPP-Net tried to fix this. With SPP-net, we calculate the CNN representation for the entire image only once and can use that to calculate the CNN representation for each patch generated by Selective Search. This can be done by performing a pooling type of operation on JUST that section of the feature maps of the last conv layer that corresponds to the region. The rectangular section of conv layer corresponding to a region can be calculated by projecting the region on the conv layer by taking into account the downsampling happening in the intermediate layers(simply dividing the coordinates by 16 in case of VGG).
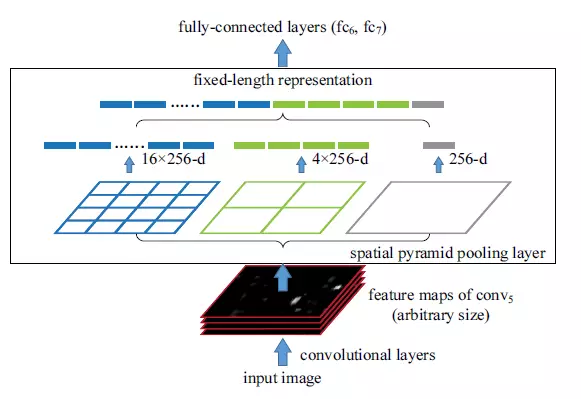
The main challenge with this approach is we need to generate the fixed size of input for the fully connected layers of the CNN and use spatial pooling after the last convolutional layer. SPP layer divides a region of any arbitrary size into a constant number of bins and a max pool is performed on each of the bins. Since the number of bins remains the same, a constant size vector is produced.
However, there was one big drawback with SPP net, it was not trivial to perform back-propagation through spatial pooling layer. Hence, the network only fine-tuned the fully connected part of the network. SPP-Net paved the way for the more popular Fast R- CNN which we will see next.
Fast R-CNN
This is faster than R-CNN. The approach is almost similar to R-CNN, The selective search method to extract ~2000 regions from an image is skipped, instead, they feed an input image to CNN, which generates the Convolutional feature maps from where we can identify the region of proposals using selective search algorithm and wrap them into squares. RoI pooling layer produces the fixed-size feature maps from non-uniform inputs by doing max-pooling on the inputs and that is fed into a fully connected layer. Softmax layer is added instead of SVM at last to predict the class of the proposed region and offset values for the bounding box.
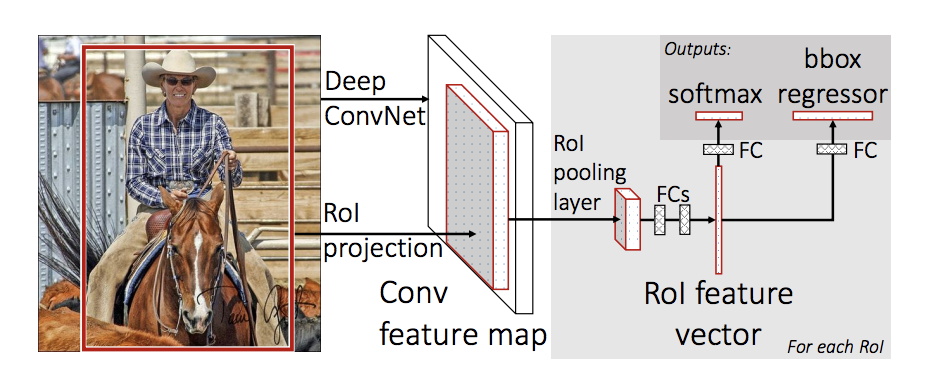
R-CNN & Fast R-CNN both use the selective search method to find the region proposals which are time-consuming and slow which affects the performance of the network.
Selective Search
1. Generate initial sub-segmentation, we generate many candidate regions
2. Use a greedy algorithm to recursively combine similar regions into larger ones
3. Use the generated regions to produce the final candidate region proposals
Faster R-CNN overcomes this issue by proposing the special network and eliminating the selective search method.
Faster R-CNN: Faster R-CNN is a single, unified network for object detection. The Regional Proposal Network (RPN) module serves as the ‘attention’ of this unified network.
RPN
Similar to Fast R-CNN, the image is provided as an input to a convolutional network which provides a convolutional feature map and RPN is used to Predict the region proposals those are then reshaped using an RoI pooling layer which is then used to classify the image within the proposed region and predict the offset values for the bounding boxes.
From the original paper:
“An RPN is a fully convolutional network that simultaneously predicts object bounds and objectness scores at each position. The RPN is trained end-to-end to generate high-quality region proposals, which are used by Fast R-CNN for detection.”
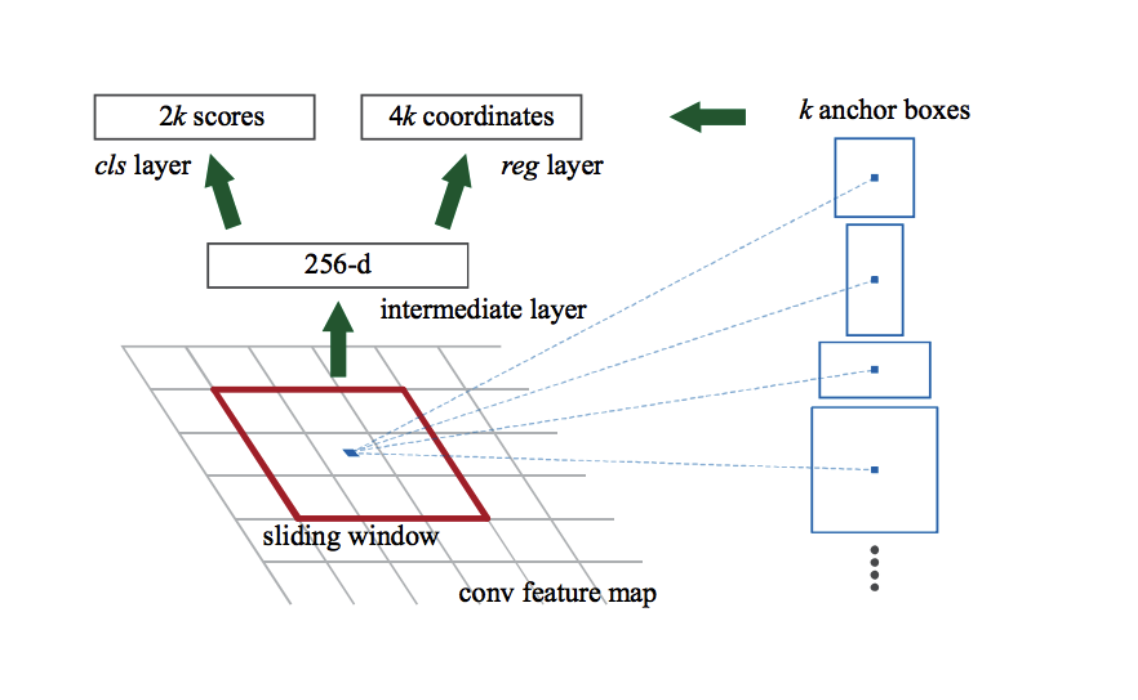
RPNs are used for efficient and accurate region proposal generation. By sharing convolutional features with the down-stream detection network, the region proposal step is nearly cost-free. The learned RPN also improves region proposal quality and thus the overall object detection accuracy.
Faster R–CNN
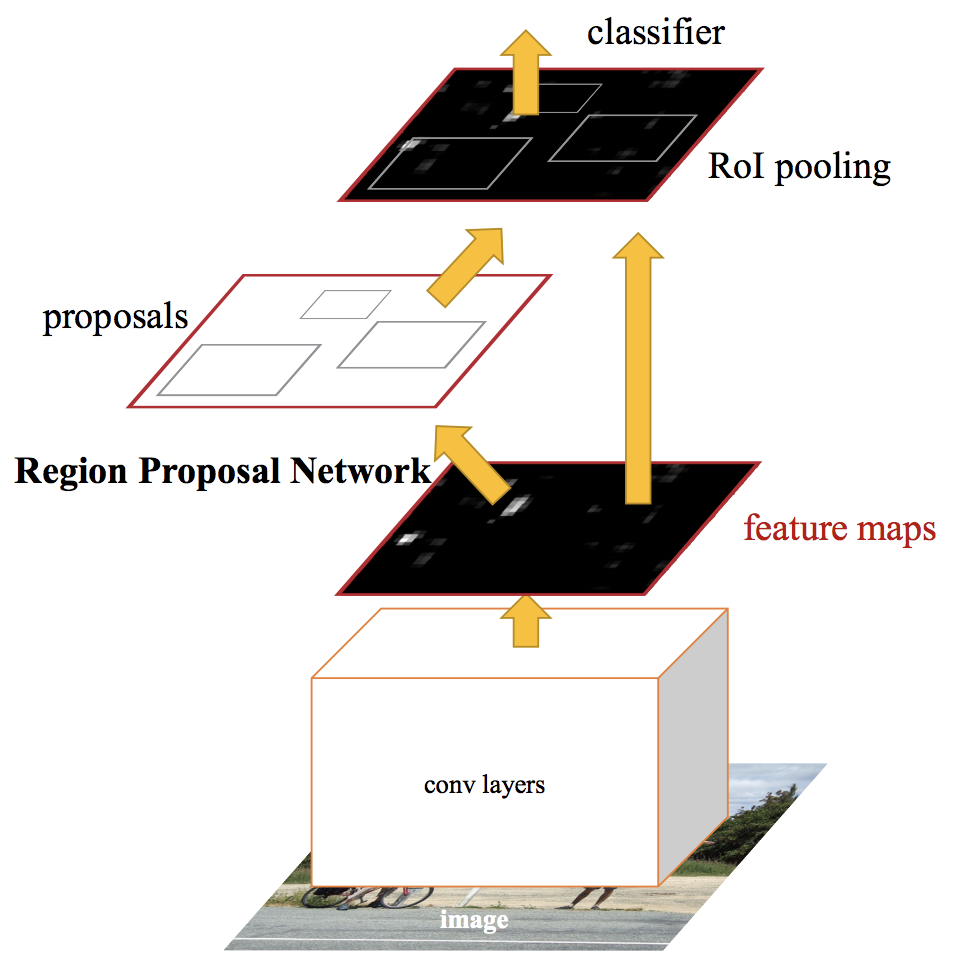
Faster R-CNN is much faster than its predecessors. Therefore, it can even be used for real-time object detection, However, there are few problems with ‘sliding window’ approach :
(1) How do we know the size of the window so that it always contains the object? Different types of objects (Bus and Tree), even the same type of objects (e.g. a small building and a large building) can be of varying sizes as well.
(2) Aspect ratio (the ratio of height to width of a bounding box). A lot of objects can be present in various shapes like a building footprint that will have a different aspect ratio than a tree.
To solve these problems, we would have to try out different sizes/shapes of sliding window, which is very computationally intensive, especially with deep neural networks.

Regression-based object detectors
So far, all the methods discussed handled detection as a classification problem by building a pipeline where first object proposals are generated and then these proposals are sent to classification/regression heads. However, there are a few methods that pose detection as a regression problem. Two of the most popular ones are YOLO and SSD. These detectors are also called single shot detectors.
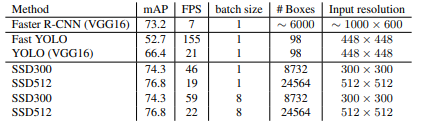
The region proposal algorithms usually have slightly better accuracy but slower to run, while single-shot algorithms like SSD & YOLO are more efficient and have good accuracy.
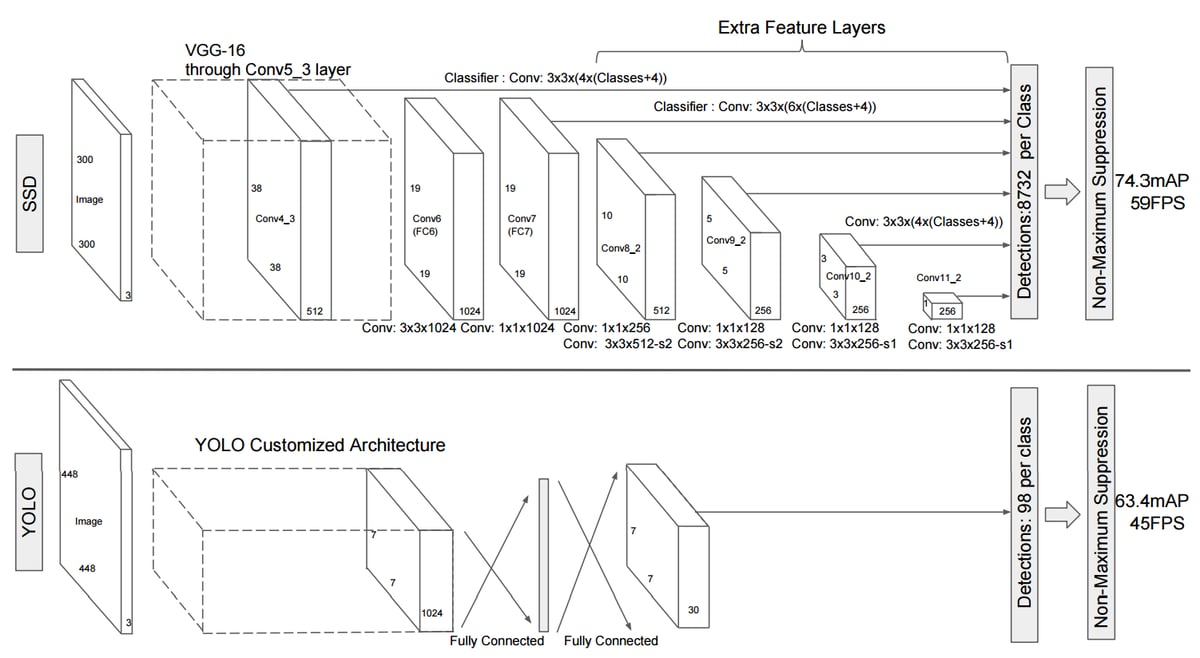
SSD
Instead of using a sliding window, SSD divides the image using a grid and have each grid cell be responsible for detecting objects in that region of the image. Each grid cell in the SSD can be assigned with multiple anchor/prior boxes. These anchor boxes are predefined and each one is responsible for size and shape within a grid cell.
The SSD, discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location.
At prediction time, the network generates scores for the presence of each object category in each default box and produces adjustments to the box to better match the object shape. Additionally, the network combines predictions from multiple feature maps with different resolutions to naturally handle objects of various sizes.
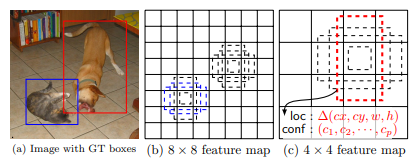
“SSD (that uses multi-scale convolutional feature maps at the top of the network instead of fully connected layers as YOLO does) is faster and more accurate than YOLO.”
The fact that SSD uses various feature maps to combine predictions results in an increased number of detections per class and image and the varying resolution on these feature maps leads to increased capabilities of detecting objects of different sizes.
YOLO
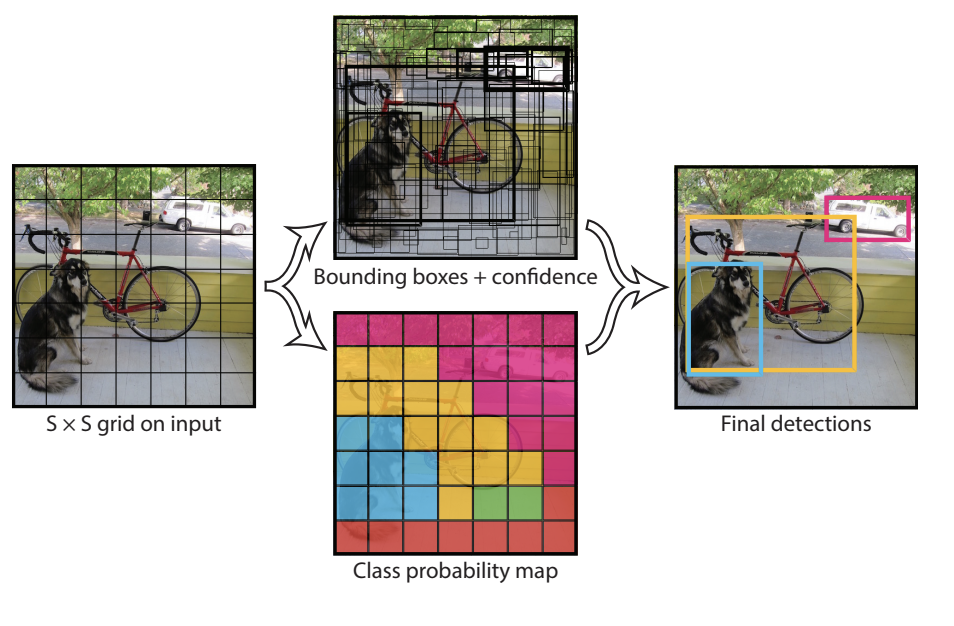
The YOLO network divides images into a grid with SxS cells, and the grid then generates M predictions for bounding boxes (SxSxM boxes in total). Each bounding box is limited to having only one class during the time of prediction, which restricts the network from finding smaller objects.The bounding boxes having the class probability above a threshold value is selected and used to locate the object within the image. YOLO unifies the task of object detection and the framing of the detected objects as the spatial location of the bounding boxes are treated as a regression problem. As of this, the entire process of calculating class probabilities and predicting bounding boxes is executed in one single ANN, which enables optimized end-to-end training of the network, and enables the YOLO network to perform at a high FPS.
As networks such as Fast R-CNN, Faster R-CNN,and SSD were released the YOLO network was improved to YOLOv2 (YOLO9000), which is a more accurate detector that is still fast. Instead of scaling up the YOLO network, simplifying the network has made the representation easier to learn. The aim of YOLO9000 was to release a better version of the YOLO network, and some of the changes in YOLOv2 are the following:
-
Batch Normalization: Helps to regularize the model and improved training converge.
-
High-Resolution Classifier: Fine tunes the classification network at a higher resolution.
-
Convolution With Anchor Boxes: YOLO uses bounding boxes for framing the objects, whereas YOLOv2 is inspired by Faster R-CNN and utilizes Anchor Boxes instead, predicting offset and confidences for these.
-
Multi-Scale Training: By training on various input dimensions, the network is forced to perform well on various input dimensions. This also leaves the network with a good payoff between accuracy and speed depending on the requirements of the application.
-
Joint Classification and Detection: Utilizing WordTree the authors of YOLOv2 were able to combine multiple datasets in hierarchies, and therefore train hierarchies of objects such as animal families. This enables the network to train on more data and to further refine the detection of objects.

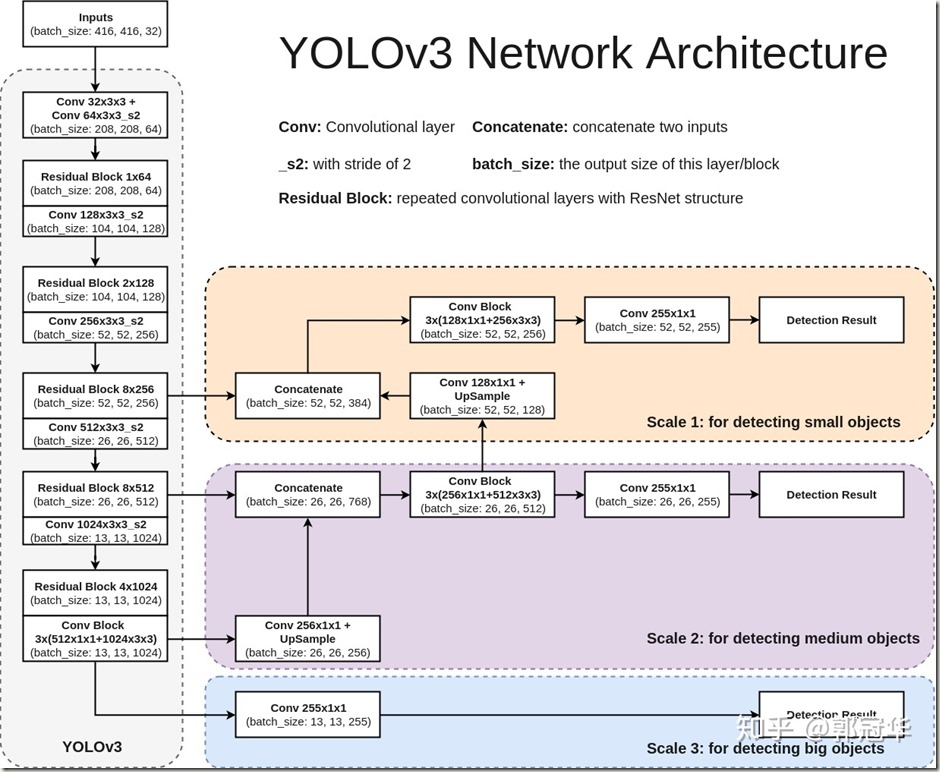
The development of YOLOv3 built upon YOLOv2 but introduced changes such as multi-scale predictions, an improved backbone classifier and a new network for feature extraction.
YOLO V3 was implemented using a darknet framework, which originally has a 53 layer network trained on Imagenet. For the task of detection, 53 more layers are added to it, giving us a 106 layer fully convolutional underlying architecture for YOLO V3. Because of this reason, YOLO V3 is slower compared to YOLO V2 but works better in all other aspects.
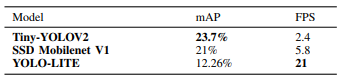
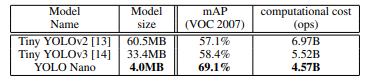
As YOLO, YOLOv2, and YOLOv3 require large amounts of computational power for inference, the Tiny YOLO network was developed and optimized for use on embedded systems and mobile devices. The Tiny YOLO networks are inferior to the full YOLO networks in terms of mAP but run at significantly higher FPS.
There are also a couple of novel models designed like YOLO-LITE, YOLO Nano to create a smaller, faster, and more efficient model increasing the accessibility of real-time object detection to a variety of devices.
Most of the modern accurate models require many GPUs for training with a large mini-batch size, and doing this with one GPU makes the training really slow and impractical. YOLO V4 addresses this issue by making an object detector that can be trained on a single GPU with a smaller mini-batch size. This makes it possible to train a super fast and accurate object detector with a single 1080 Ti or 2080 Ti GPU. Achieves state-of-the-art results (43.5% AP) for real-time object detection and is able to run at a speed of 65 FPS on a V100 GPU. It is also possible to train this state-of-the-art object detector on a single conventional GPU with 8/16 GB of RAM.
Some of the key points of YOLO V4:
-
It is an efficient and powerful object detection model that enables anyone with a 1080 Ti or 2080 Ti GPU to train a super fast and accurate object detector.
-
YOLOv4 consists of Backbone: CSPDarknet53 ; Neck: SPP , PAN ;Head: YOLOv3.
-
The influence of state-of-the-art “Bag-of-Freebies”(Methods that can make the object detector receive better accuracy without increasing the inference cost. These methods only change the training strategy or only increase the training cost) and “Bag-of-Specials”(Those plugin modules and post-processing methods that only increase the inference cost by a small amount but can significantly improve the accuracy of object detection) object detection methods during detector training has been verified
-
YOLOV4, including some features such as Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP)(CSPDarknet53 as the feature-extractor model for the GPU version.), Cross mini-Batch Normalization (CmBN), Self-adversarial-training (SAT) and Mish-activation, Mosaic data augmentation, DropBlock regularization, and CIoU loss. These are referred to as universal features because they should work well independently from the computer vision tasks, datasets and models, also now more efficient and suitable for single GPU training.
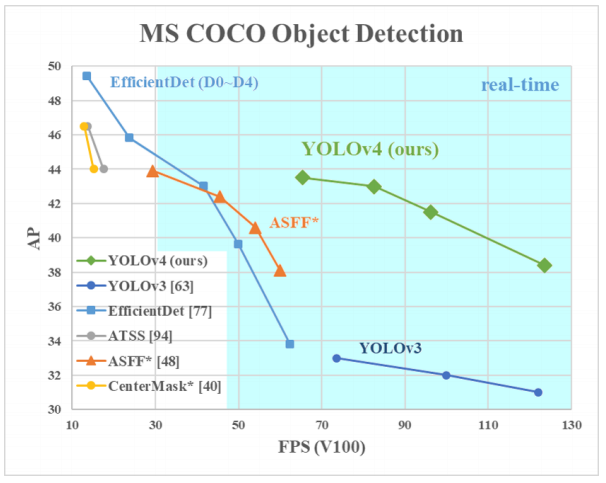
YOLOv5 was released by Glenn Jocher on June 9, 2020. It follows the recent releases of YOLO V4 and EfficientDet.
YOLOv5 is faster, smaller, and easier to use. It is natively implemented in PyTorch (rather than Darknet), modifying the architecture and exporting to many deploy environments is straightforward.
-
SIZE: YOLOv5 is about 88% smaller than YOLOv4 (27 MB vs 244 MB)
-
SPEED: YOLOv5 is about 180% faster than YOLOv4 (140 FPS vs 50 FPS)
-
ACCURACY: YOLOv5 is roughly as accurate as YOLOv4 on the same task (0.895 mAP vs 0.892 mAP)
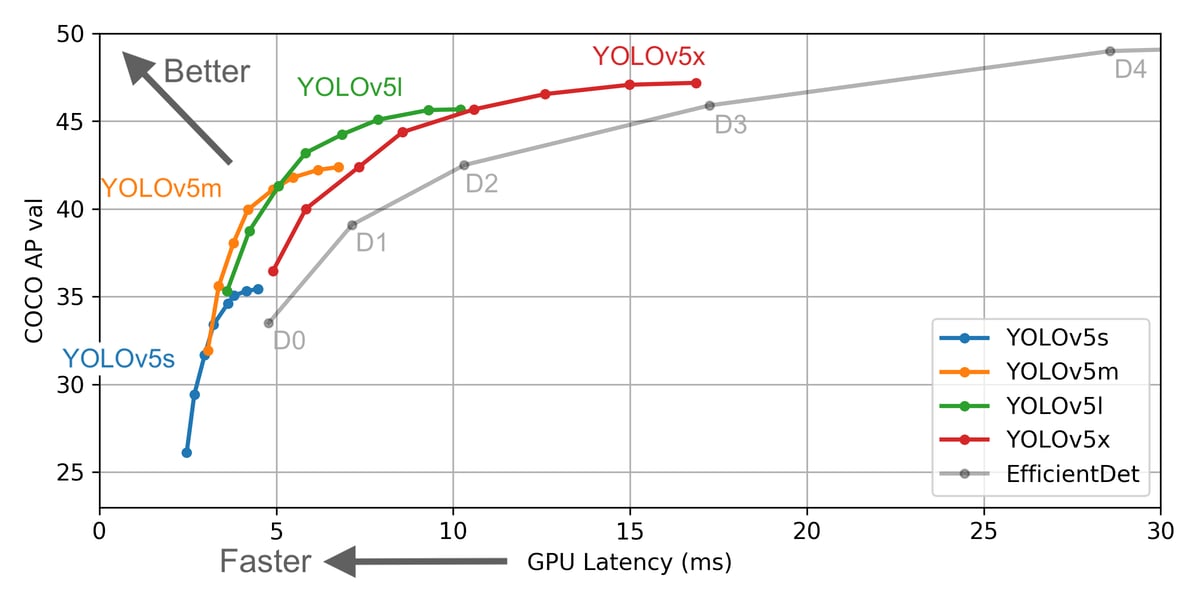 YOLO V5 performance
YOLO V5 performance
Transformers based object detector:
Transformers are a deep learning architecture that has gained popularity in recent years. They rely on a simple yet powerful mechanism called attention, which enables AI models to selectively focus on certain parts of their input and thus reason more effectively. Transformers have been widely applied to problems with sequential data, in particular in natural language processing (NLP) tasks such as language modeling and machine translation, and have also been extended to tasks as diverse as speech recognition, symbolic mathematics, and reinforcement learning. But, perhaps surprisingly, computer vision has not yet been swept up by the Transformer revolution.
Bonus article to dive bit deeper into Self-Attention In Computer Vision !
Detection Transformers (DETR)
An important new approach to object detection and panoptic segmentation. It is the first object detection framework to successfully integrate Transformers as a central building block in the detection pipeline.
DETR casts the object detection task as an image-to-set problem. Given an image, the model must predict an unordered set (or list) of all the objects present, each represented by its class, along with a tight bounding box surrounding each one.
DETR matches the performance of state-of-the-art methods, such as the well-established and highly optimized Faster R-CNN baseline on the challenging COCO object detection data set, while also greatly simplifying and streamlining the architecture.
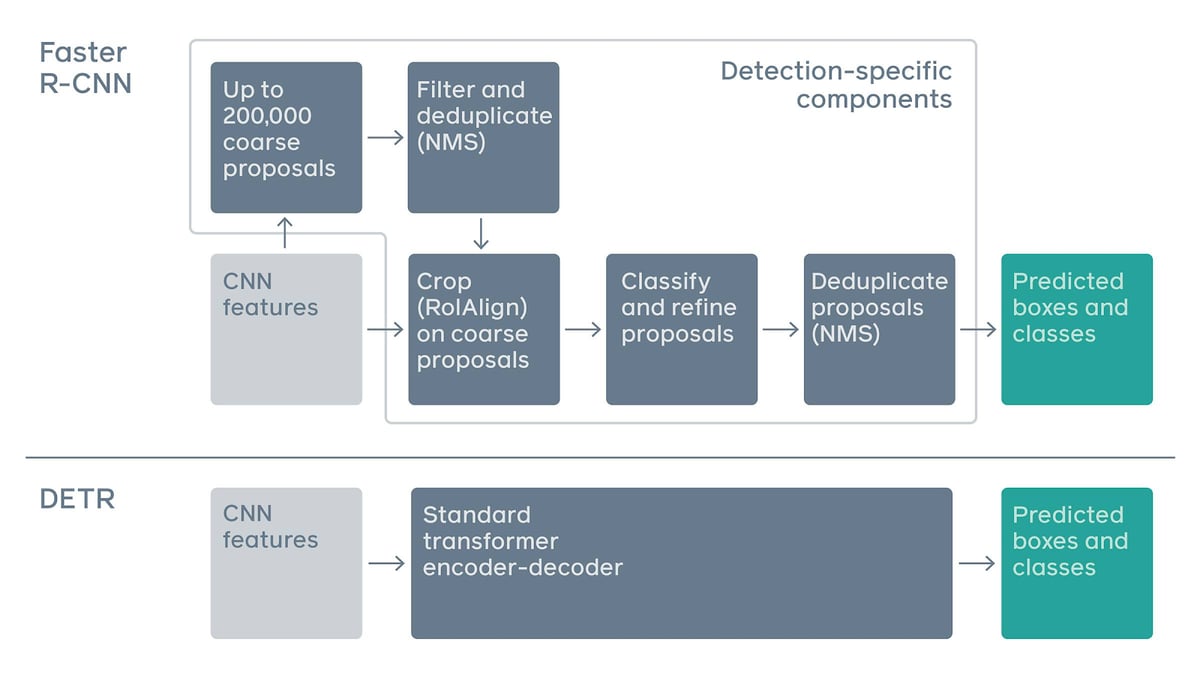
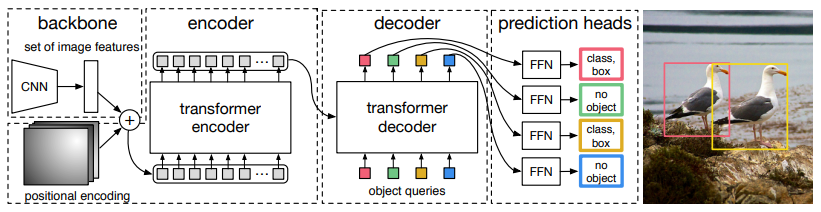
The overall DETR architecture is actually pretty easy to understand. It contains three main components:
-
a CNN backbone
-
an Encoder-Decoder transformer
-
a simple feed-forward network
-
Here, the CNN backbone generates a feature map from the input image. Then the output of the CNN backbone is converted into a one-dimensional feature map that is passed to the Transformer encoder as input. The output of this encoder is the N number of fixed length embedding (vectors), where N is the number of objects in the image assumed by the model.
-
The Transformer decoder decodes these embedding into bounding box coordinates with the help of self and encoder-decoder attention mechanisms.
-
Finally, the feed-forward neural networks predict the normalized center coordinates, height, and width of the bounding boxes and the linear layer predicts the class label using a softmax function.
DETR’s authors say that this novel architecture can also help improve the interpretability of computer vision models. Because it relies on attention mechanisms, it is easy to see what parts of an image the network is looking at when it makes a prediction.
We reached the end of the blog but exploration is never ending!

Reference:
[1]A Gentle Introduction to YOLO v4 for Object detection in Ubuntu 20.04
[2]Is YOLO really better than SSD?.
[3]Zero to Hero: Guide to Object Detection using Deep Learning: Faster R-CNN,YOLO,SSD
[4]R-CNN, Fast R-CNN, Faster R-CNN, YOLO — Object Detection Algorithms
[5]YOLO v4: Optimal Speed & Accuracy for object detection
[[6]A Gentle Introduction to YOLO v4 for Object detection in Ubuntu 20.04
[7]End-to-end object detection with Transformers
[8] https://models.roboflow.ai/object-detection/yolov5
Additional Object Detectors:
[1] Mask R-CNN
[2]DSSD (Deconvolutional Single Shot Detector)
[3]RetinaNet
[4]M2Det
[5]RefineDet
[6]Relation Networks for Object Detection
[7]DCNv2
[8]NAS-FPN
[9]Cornernet
[10] EfficientDet






