Manually managing the lifecycle of Kubernetes nodes can become difficult as the cluster scales. Especially if your clusters are multi-tenant and self-managed. You may need to replace nodes for various reasons, such as OS upgrades and security patches. One of the biggest challenges is how to terminate nodes without disturbing tenants. In this post, I’ll describe the problems we encountered administering Yelp’s clusters and the solutions we implemented.
Problems
At Yelp we use PaaSTA for building, deploying and running services. Initially, PaaSTA just supported stateless services. This meant it was relatively easy to replace nodes since we only needed to gracefully remove the pods from our service mesh on shutdown. However, it may still result in services with fewer replicas than expected. We now run many diverse workloads in our clusters including stateful services, batch jobs and pipeline tasks. Some workloads run on private pools (groups of nodes) but many workloads run in shared pools. At Yelp, we use Clusterman to manage our Kubernetes pools. Clusterman is an open source autoscaling engine that we initially wrote to scale our Mesos clusters and subsequently adapted to support Kubernetes.
There are many challenges in multi-tenant clusters since tenants and cluster administrators often work on different teams (and maybe different time zones). Cluster administrators often need to perform maintenance on their clusters, including the replacement of nodes for security fixes, OS upgrades, or other tasks. Given the diversity of workloads running on the clusters, it’s very difficult for administrators to do so safely without working closely with the workload owners to ensure that the termination and replacement pods are done safely. This can also be difficult in Yelp’s distributed, asynchronous work environment. Maintenance can take a long time given the diverse set of workloads and large size of the clusters. Additionally, manual work is error-prone, and a human is more likely to mistakenly delete the wrong node or pod! We decided to tackle the problems in two parts:
- Protecting workloads from disruptions.
- Node replacement automation.
1. Protecting workloads from disruptions
A good place to start is the Kubernetes documentation on disruptions. There are two types of disruptions:
- Voluntary (by cluster admin): draining a node for an upgrade or a scaling-down
- Involuntary: hardware failures, kernel panic, network partition, etc.
We will focus on voluntary disruptions in our case. Pod Disruption Budget (PDB) is the industry standard to protect Kubernetes workloads from voluntary disruptions. “As an application owner, you can create a PDB for each application. A PDB limits the number of pods of a replicated application that are down simultaneously from voluntary disruptions. For example, a quorum-based application would like to ensure that the number of replicas running is never brought below the number needed for a quorum. A web front-end might want to ensure that the number of replicas serving load never falls below a certain percentage of the total.” (Kubernetes, Pod Disruption Budget). At Yelp we have some sensitive workloads like Nrtsearch and Cassandra where we don’t want to disrupt more than one pod at a time in each cluster.
If you have bare (without controller) pods in your cluster you should consider some limitations to using PDB. Specifically, you can not use the maxUnavailable and percentage fields.
Besides PDBs, we also evaluated some alternative ways to prevent involuntary disruptions. For example by using Validating Admission Webhook and PreStop Hooks to protect workloads but we decided to continue with PDBs since it was designed for exactly this use case.
2. Node replacement automation
Once we defined PDBs for all the applications running on our clusters, we moved on to thinking about the automation needed to replace nodes. We chose to add features to Clusterman to manage node replacement. Before getting into the solution, it is helpful to know a little about Clusterman’s internal components.
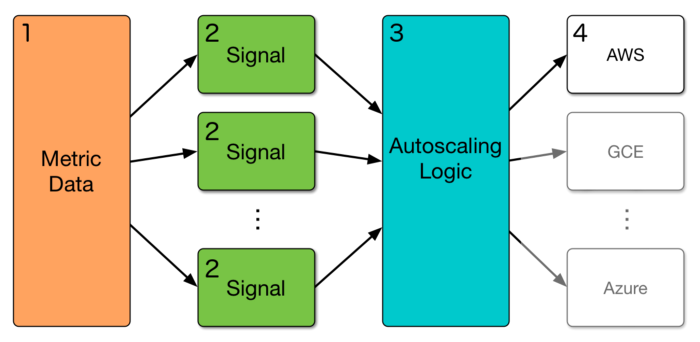
- Metrics Data Store: All relevant data used by scaling signals is written to a single data store for a single source of truth about historical cluster state. At Yelp, we use AWS DynamoDB for this datastore. Metrics are written to the datastore via a separate metrics library.
- Pluggable Signals: Metrics (from the data store) are consumed by signals (small bits of code that are used to produce resource requests). Signals run in separate processes configured by supervisord, and use Unix sockets to communicate.
- Core Autoscaler: The autoscaler logic consumes resource requests from the signals and combines them to determine how much to scale up or down via the cloud provider.
We added two more components to solve the node replacement problem: Drainer and Node Migration Batch
Drainer
The Drainer is the component which drains pods from the node before terminating. It may drain and terminate nodes for three reasons:
- Spot instance interruptions
- Node migrations
- The autoscaler scaling down
The Drainer uses API-initiated eviction for node migrations and scaling down. API-initiated eviction is the process by which you use the Eviction API to create an Eviction object that triggers graceful pod termination. Crucially, API-initiated evictions respect your configured PodDisruptionBudgets and terminationGracePeriodSeconds.
The Drainer taints nodes as a first step to prevent the Kubernetes Scheduler from scheduling new pods to the draining node. Then it tries to evict the pods periodically until the node is empty. After evicting all pods, it deletes the node and terminates the instance. In cases where we have defined PDBs that are very strict or there is not much spare capacity in the pool, this can take a long time. We’ve added a user-configurable threshold to prevent very long (or indefinitely) draining nodes. The Drainer will then forcibly delete or un-taint the node depending on the uptime requirements of the workloads running in that pool.
Node Migration
The Node Migration batch allows Clusterman to replace nodes in a pool according to various criteria. This automates the process of replacing nodes running software with security vulnerabilities, upgrading the kernel we run, or upgrading the whole Operating System to newer versions. It chooses which nodes to replace and sends them to the Drainer to terminate gracefully, continuously monitoring the pool capacity to ensure we don’t impact the availability of workloads running on the cluster.
We’ve created NodeMigration Custom Resource to specify migration requirements. We can request migration based on kernel version, OS version, instance type and uptime. For instance, the target of the following manifest is to keep nodes uptime less than 30 days:
apiVersion: "clusterman.yelp.com/v1"
kind: NodeMigration
metadata:
name: my-test-migration-220912
labels:
clusterman.yelp.com/migration_status: pending
spec:
cluster: mycluster
pool: default
condition:
trait: uptime
operator: lt
target: 30d
Conclusion
Finally, we can describe the high level design of our new system as the following.
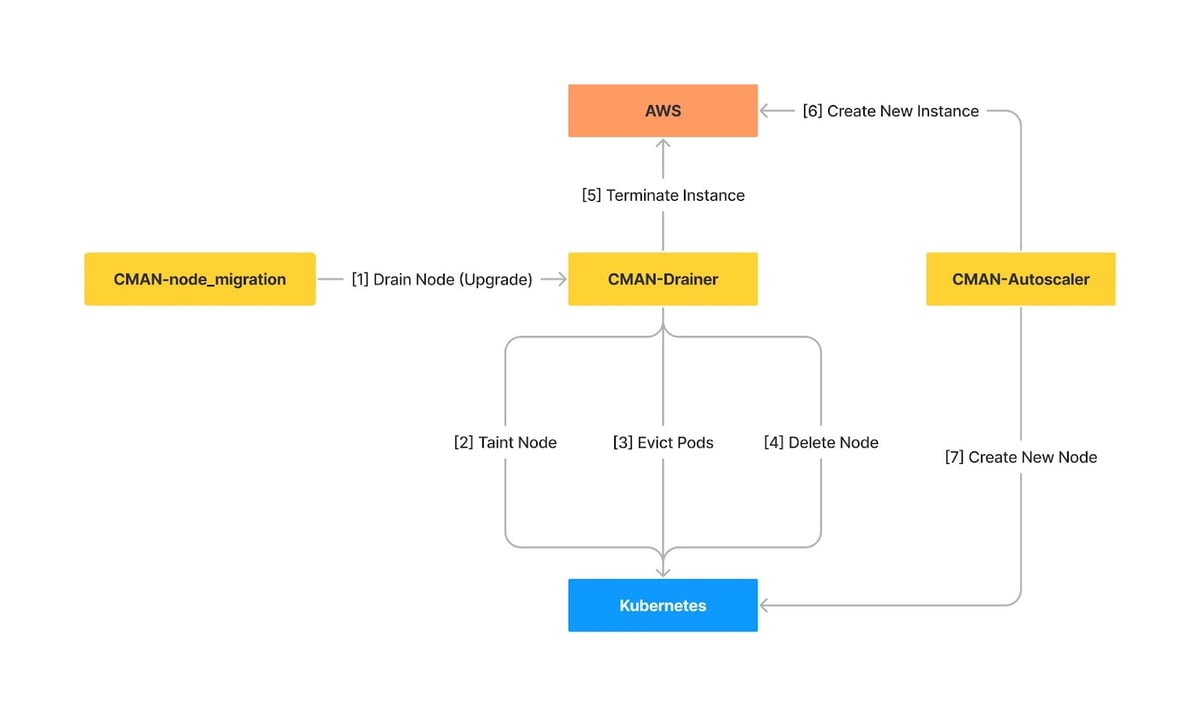
Now that we have this system running we are able to more easily deploy new versions of Ubuntu or keep nodes fresh. We can create migration manifests using a CLI tool and Clusterman will gradually replace all the instances whilst ensuring that the workloads are not disrupted and that new nodes are running correctly
Acknowledgements
This was a cross-team project between Yelp’s Infrastructure and Security team. Many thanks to Matteo Piano for being the main part of the project and leading it, and to the many teams at Yelp that contributed to making the new system a success. We want to thank Compute Infra, Security Effectiveness and any of the other teams that contributed by making PDBs. Additionally, thanks to Matthew Mead-Briggs and Andrea Dante Bozzola for their managerial support.






