2-Week Roadmap to Mastering Transformers for Top Tech Interviews
For AI scientists, engineers, and advanced students targeting roles at leading tech companies, a deep and nuanced understanding of Transformers is non-negotiable. Technical interviews will probe not just what these models are, but how they work, why certain design choices were made, their limitations, and how they compare to alternatives. This intensive two-week roadmap is designed to build that comprehensive knowledge, focusing on both foundational concepts and advanced topics crucial for interview success.The plan emphasizes a progression from the original "Attention Is All You Need" paper through key architectural variants and practical considerations. It encourages not just reading, but actively engaging with the material, for instance, by conceptually implementing mechanisms or focusing on the trade-offs discussed in research.
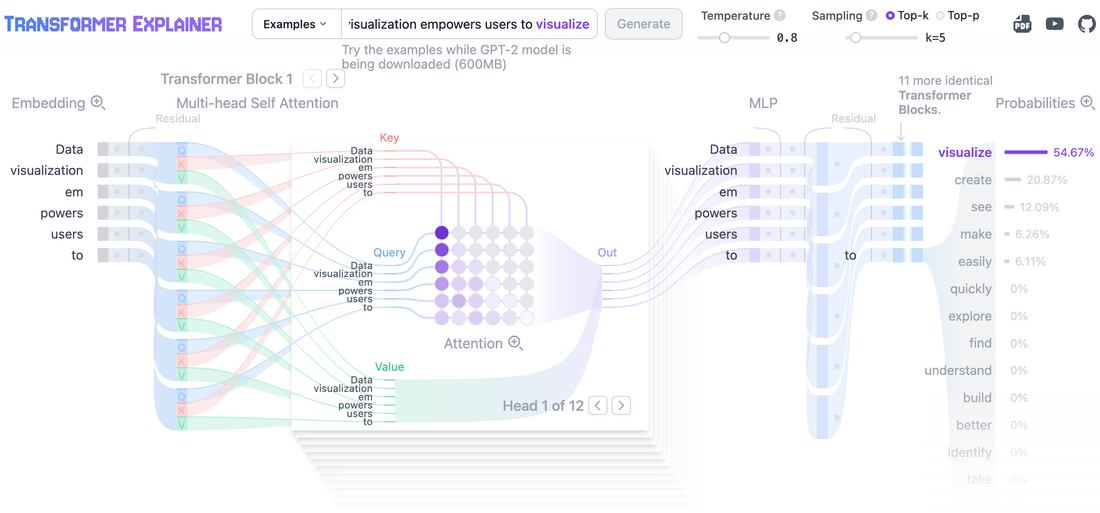
Week 1: Foundations & Core Architectures
The first week focuses on understanding the fundamental building blocks and key early architectures of Transformer models.
Days 1-2: Deep Dive into "Attention Is All You Need"
- Topic/Focus: Gain a deep understanding of the seminal "Attention Is All You Need" paper by Vaswani et al. (2017).
- Key Concepts:Scaled Dot-Product Attention: Grasp the mechanics of Q (Query), K (Key), and V (Value).Multi-Head Attention: Understand how multiple attention heads enhance model performance.Positional Encoding (Sinusoidal): Learn how positional information is incorporated without recurrence or convolution.Encoder-Decoder Architecture: Familiarize yourself with the overall structure of the original Transformer.
- Scaled Dot-Product Attention: Grasp the mechanics of Q (Query), K (Key), and V (Value).
- Multi-Head Attention: Understand how multiple attention heads enhance model performance.
- Positional Encoding (Sinusoidal): Learn how positional information is incorporated without recurrence or convolution.
- Encoder-Decoder Architecture: Familiarize yourself with the overall structure of the original Transformer.
- Activities/Goals:Thoroughly read and comprehend the original paper, focusing on the motivation behind each component.Conceptually implement (or pseudo-code) a basic scaled dot-product attention mechanism.Understand the role of the scaling factor, residual connections, and layer normalization.
- Thoroughly read and comprehend the original paper, focusing on the motivation behind each component.
- Conceptually implement (or pseudo-code) a basic scaled dot-product attention mechanism.
- Understand the role of the scaling factor, residual connections, and layer normalization.
Days 3-4: BERT:
- Topic/Focus: Explore BERT (Bidirectional Encoder Representations from Transformers) and its significance in natural language understanding (NLU).
- Key Concepts:BERT's Architecture: Understand its encoder-only Transformer structure.Pre-training Objectives: Deeply analyze Masked Language Model (MLM) and Next Sentence Prediction (NSP) pre-training tasks.Bidirectionality: Understand how BERT's bidirectional nature aids NLU tasks.
- BERT's Architecture: Understand its encoder-only Transformer structure.
- Pre-training Objectives: Deeply analyze Masked Language Model (MLM) and Next Sentence Prediction (NSP) pre-training tasks.
- Bidirectionality: Understand how BERT's bidirectional nature aids NLU tasks.
- Activities/Goals:Study Devlin et al.'s (2018) "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" paper.
- Study Devlin et al.'s (2018) "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" paper.
Days 5-6: GPT:
- Topic/Focus: Delve into the Generative Pre-trained Transformer (GPT) series and its generative capabilities.
- Key Concepts:GPT's Architecture: Understand its decoder-only structure.Autoregressive Language Modeling: Grasp how GPT generates text sequentially.Generative Pre-training: Learn about the pre-training methodology.
- GPT's Architecture: Understand its decoder-only structure.
- Autoregressive Language Modeling: Grasp how GPT generates text sequentially.
- Generative Pre-training: Learn about the pre-training methodology.
- Activities/Goals:Study Radford et al.'s GPT-1 paper ("Improving Language Understanding by Generative Pre-Training") and conceptually extend this knowledge to GPT-2/3 evolution.Contrast GPT's objectives with BERT's, considering their implications for text generation and few-shot learning.
- Study Radford et al.'s GPT-1 paper ("Improving Language Understanding by Generative Pre-Training") and conceptually extend this knowledge to GPT-2/3 evolution.
- Contrast GPT's objectives with BERT's, considering their implications for text generation and few-shot learning.
Day 7: Consolidation: Encoder, Decoder, Enc-Dec Models
- Topic/Focus: Consolidate your understanding of the different types of Transformer architectures.
- Key Concepts: Review the original Transformer, BERT, and GPT.
- Activities/Goals:Compare and contrast encoder-only (BERT-like), decoder-only (GPT-like), and full encoder-decoder (original Transformer, T5-like) models.Map their architectures to their primary use cases (e.g., NLU, generation, translation).Diagram the information flow within each architecture.
- Compare and contrast encoder-only (BERT-like), decoder-only (GPT-like), and full encoder-decoder (original Transformer, T5-like) models.
- Map their architectures to their primary use cases (e.g., NLU, generation, translation).
- Diagram the information flow within each architecture.
Week 2: Advanced Topics & Interview Readiness
The second week shifts to advanced Transformer concepts, including efficiency, multimodal applications, and preparation for technical interviews.
Days 8-9: Efficient Transformers
- Topic/Focus: Explore techniques designed to make Transformers more efficient, especially for long sequences.
- Key Papers/Concepts: Longformer, Reformer, (Optionally BigBird).
- Activities/Goals:Study mechanisms for handling long sequences, such as local + global attention (Longformer) and Locality-Sensitive Hashing (LSH) with reversible layers (Reformer).Understand how these models achieve better computational complexity (linear or O(NlogN)).
- Study mechanisms for handling long sequences, such as local + global attention (Longformer) and Locality-Sensitive Hashing (LSH) with reversible layers (Reformer).
- Understand how these models achieve better computational complexity (linear or O(NlogN)).
Day 10: Vision Transformer (ViT)
- Topic/Focus: Understand how Transformer architecture has been adapted for computer vision tasks.
- Key Paper: Dosovitskiy et al. (2020) "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale".
- Activities/Goals:Understand how images are processed as sequences of patches.Explain the role of the [CLS] token, patch embeddings, and positional embeddings for vision.Contrast ViT's approach and inductive biases with traditional Convolutional Neural Networks (CNNs).
- Understand how images are processed as sequences of patches.
- Explain the role of the [CLS] token, patch embeddings, and positional embeddings for vision.
- Contrast ViT's approach and inductive biases with traditional Convolutional Neural Networks (CNNs).
Day 11: State Space Models (Mamba)
- Topic/Focus: Gain a high-level understanding of State Space Models (SSMs), particularly Mamba.
- Key Paper: Gu & Dao (2023) "Mamba: Linear-Time Sequence Modeling with Selective State Spaces".
- Activities/Goals:Get a high-level understanding of SSM principles (continuous systems, discretization, selective state updates).Focus on Mamba's linear-time complexity advantage for very long sequences and its core mechanism.
- Get a high-level understanding of SSM principles (continuous systems, discretization, selective state updates).
- Focus on Mamba's linear-time complexity advantage for very long sequences and its core mechanism.
Day 12: Inference Optimization
- Topic/Focus: Learn about crucial techniques for deploying large Transformer models efficiently.
- Key Concepts: Quantization, Pruning, and Knowledge Distillation.
- Activities/Goals:Research and summarize the goals and basic mechanisms of these techniques.Understand why they are essential for deploying large Transformer models in real-world applications.
- Research and summarize the goals and basic mechanisms of these techniques.
- Understand why they are essential for deploying large Transformer models in real-world applications.
Days 13-14: Interview Practice & Synthesis
- Topic/Focus: Apply your knowledge to common interview questions and synthesize your understanding across all topics.
- Key Concepts: All previously covered topics.
- Activities/Goals:Practice explaining trade-offs, such as:"Transformer vs. LSTM?""BERT vs. GPT?""When is Mamba preferred over a Transformer?""ViT vs. CNN?"Formulate answers that demonstrate a deep understanding of the underlying principles, benefits, and limitations of each architecture.
- Practice explaining trade-offs, such as:"Transformer vs. LSTM?""BERT vs. GPT?""When is Mamba preferred over a Transformer?""ViT vs. CNN?"
- "Transformer vs. LSTM?"
- "BERT vs. GPT?"
- "When is Mamba preferred over a Transformer?"
- "ViT vs. CNN?"
- Formulate answers that demonstrate a deep understanding of the underlying principles, benefits, and limitations of each architecture.
This roadmap is intensive but provides a structured path to building the deep, comparative understanding that top tech companies expect. The progression from foundational papers to more advanced variants and alternatives allows for a holistic grasp of the Transformer ecosystem. The final days are dedicated to synthesizing this knowledge into articulate explanations of architectural trade-offs-a common theme in technical AI interviews.
Recommended Resources
To supplement the study of research papers, the following resources are highly recommended for their clarity, depth, and practical insights:Books:
- "Natural Language Processing with Transformers, Revised Edition" by Lewis Tunstall, Leandro von Werra, and Thomas Wolf: Authored by engineers from Hugging Face, this book is a definitive practical guide. It covers building, debugging, and optimizing Transformer models (BERT, GPT, T5, etc.) for core NLP tasks, fine-tuning, cross-lingual learning, and deployment techniques like distillation and quantization. It's updated and highly relevant for practitioners.
- "Build a Large Language Model (From Scratch)" by Sebastian Raschka: This book offers a hands-on approach to designing, training, and fine-tuning LLMs using PyTorch and Hugging Face. It provides a strong blend of theory and applied coding, excellent for those who want to understand the inner workings deeply.
- "Hands-On Large Language Models" by Jay Alammar: Known for his exceptional visual explanations, Alammar's book simplifies complex Transformer concepts. It focuses on intuitive understanding and deploying LLMs with open-source tools, making it accessible and practical.
Influential Blog Posts & Online Resources:
- Excellent visual explainer for how Transformers work
- Jay Alammar's "The Illustrated Transformer" : A universally acclaimed starting point for understanding the core Transformer architecture with intuitive visualizations of self-attention, multi-head attention, and the encoder-decoder structure.
- Jay Alammar's "The Illustrated GPT-2" : Extends the visual explanations to decoder-only Transformer language models like GPT-2, clarifying their autoregressive nature and internal workings.
- Lilian Weng's Blog Posts: (e.g., "Attention? Attention!" and "Large Transformer Model Inference Optimization" ): These posts offer deep dives into specific mechanisms like attention variants and comprehensive overviews of advanced topics like inference optimization techniques.
- Peter Bloem's "Transformers from scratch" : A well-written piece with clear explanations, graphics, and understandable code examples, excellent for solidifying understanding.
- Original Research Papers: Referenced throughout this article (e.g., "Attention Is All You Need," BERT, GPT, Longformer, Reformer, ViT, Mamba papers). Reading the source is invaluable.
- University Lectures: Stanford's CS224n (Natural Language Processing with Deep Learning) and CS324 (LLMs) have high-quality publicly available lecture slides and videos that cover Transformers in depth.
- Harvard NLP's "The Annotated Transformer" : A blog post that presents the original Transformer paper alongside PyTorch code implementing each section, excellent for bridging theory and practice.
By combining diligent study of these papers and resources with the structured roadmap, individuals can build a formidable understanding of Transformer technology, positioning themselves strongly for challenging technical interviews and impactful roles in the AI industry. The emphasis throughout should be on not just what these models do, but why they are designed the way they are, and the implications of those design choices.9.
25 Interview Questions on Transformers
As transformer architectures continue to dominate the landscape of artificial intelligence, a deep understanding of their inner workings is a prerequisite for landing a coveted role at leading tech companies. Aspiring machine learning engineers and researchers are often subjected to a rigorous evaluation of their knowledge of these powerful models. To that end, we have curated a comprehensive list of 25 actual interview questions on Transformers, sourced from interviews at OpenAI, Anthropic, Google DeepMind, Amazon, Google, Apple, and Meta.This list is designed to provide a well-rounded preparation experience, covering fundamental concepts, architectural deep dives, the celebrated attention mechanism, popular model variants, and practical applications.
Foundational Concepts
Kicking off with the basics, interviewers at companies like Google and Amazon often test a candidate's fundamental grasp of why Transformers were a breakthrough.
- What was the primary limitation of recurrent neural networks (RNNs) and long short-term memory (LSTMs) that the Transformer architecture aimed to solve?
- Explain the overall architecture of the original Transformer model as introduced in the paper "Attention Is All You Need."
- What is the significance of positional encodings in the Transformer model, and why are they necessary?
- Describe the role of the encoder and decoder stacks in the Transformer architecture. When would you use only an encoder or only a decoder?
- How does the Transformer handle variable-length input sequences?
The Attention Mechanism: The Heart of the Transformer
A thorough understanding of the self-attention mechanism is non-negotiable. Interviewers at OpenAI and Google DeepMind are known to probe this area in detail.
- Explain the concept of self-attention (or scaled dot-product attention) in your own words. Walk through the calculation of an attention score.
- What are the Query (Q), Key (K), and Value (V) vectors in the context of self-attention, and what is their purpose?
- What is the motivation behind using Multi-Head Attention? How does it benefit the model?
- What is the "masking" in the decoder's self-attention layer, and why is it crucial for tasks like language generation?
- Can you explain the difference between self-attention and cross-attention? Where is cross-attention used in the Transformer architecture?
Architectural Deep Dive:
Candidates at Anthropic and Meta can expect to face questions that delve into the finer details of the Transformer's building blocks.
- Describe the "Add & Norm" (residual connections and layer normalization) components in the Transformer. What is their purpose?
- What is the role of the feed-forward neural network in each layer of the encoder and decoder?
- Explain the differences in the architecture of a BERT (Encoder-only) model versus a GPT (Decoder-only) model.
- What are Byte Pair Encoding (BPE) and WordPiece in the context of tokenization for Transformer models? How do they differ?
- Discuss the computational complexity of the self-attention mechanism. What are the implications of this for processing long sequences?
Model Variants and Applications:
Questions about popular Transformer-based models and their applications are common across all top tech companies, including Apple with its growing interest in on-device AI.
- How does BERT's training objective (Masked Language Modeling and Next Sentence Prediction) enable it to learn bidirectional representations?
- Explain the core idea behind Vision Transformers (ViT). How are images processed to be used as input to a Transformer?
- What is transfer learning in the context of large language models like GPT-3 or BERT? Describe the process of fine-tuning.
- How would you use a pre-trained Transformer model for a sentence classification task?
- Discuss some of the techniques used to make Transformers more efficient, such as sparse attention or knowledge distillation.
Conclusions - The Ever-Evolving Landscape
The journey of the Transformer, from its inception in the "Attention Is All You Need" paper to its current ubiquity, is a testament to its profound impact on the field of Artificial Intelligence. We have deconstructed its core mechanisms-self-attention, multi-head attention, and positional encodings-which collectively allow it to process sequential data with unprecedented parallelism and efficacy in capturing long-range dependencies. We've acknowledged its initial limitations, primarily the quadratic complexity of self-attention, which spurred a wave of innovation leading to more efficient variants like Longformer, BigBird, and Reformer. The architectural flexibility of Transformers has been showcased by influential models like BERT, which revolutionized Natural Language Understanding with its bidirectional encoders, and GPT, which set new standards for text generation with its autoregressive decoder-only approach.
The engineering feats behind training these models on massive datasets like C4 and Common Crawl, coupled with sophisticated inference optimization techniques such as quantization, pruning, and knowledge distillation, have been crucial in translating research breakthroughs into practical applications. Furthermore, the Transformer's adaptability has been proven by its successful expansion beyond text into modalities like vision (ViT), audio (AST), and video, pushing towards unified AI architectures. While alternative architectures like State Space Models (Mamba) and Graph Neural Networks offer compelling advantages for specific scenarios, Transformers continue to be a dominant and versatile framework.
Looking ahead, the trajectory of Transformers and large-scale AI models like OpenAI's GPT-4 and GPT-4o, Google's Gemini, and Anthropic's Claude series (Sonnet, Opus) points towards several key directions. We are witnessing a clear trend towards larger, more capable, and increasingly multimodal foundation models that can seamlessly process, understand, and generate information across text, images, audio, and video. The rapid adoption of these models in enterprise settings for a diverse array of use cases, from text summarization to internal and external chatbots and enterprise search, is already underway.
However, this scaling and broadening of capabilities will be accompanied by an intensified focus on efficiency, controllability, and responsible AI. Research will continue to explore methods for reducing the computational and data hunger of these models, mitigating biases, enhancing their interpretability, and ensuring their outputs are factual and aligned with human values. The challenges of data privacy and ensuring consistent performance remain key barriers that the industry is actively working to address.A particularly exciting frontier, hinted at by conceptual research like the "Retention Layer" , is the development of models with more persistent memory and the ability to learn incrementally and adaptively over time. Current LLMs largely rely on fixed pre-trained weights and ephemeral context windows. Architectures that can store, update, and reuse learned patterns across sessions-akin to human episodic memory and continual learning-could overcome fundamental limitations of today's static pre-trained models. This could lead to truly personalized AI assistants, systems that evolve with ongoing interactions without costly full retraining, and AI that can dynamically respond to novel, evolving real-world challenges.
The field is likely to see a dual path: continued scaling of "frontier" general-purpose models by large, well-resourced research labs, alongside a proliferation of smaller, specialized, or fine-tuned models optimized for specific tasks and domains. For AI leaders, navigating this ever-evolving landscape will require not only deep technical understanding but also strategic foresight to harness the transformative potential of these models while responsibly managing their risks and societal impact. The Transformer revolution is far from over; it is continuously reshaping what is possible in artificial intelligence.
I encourage you to share your thoughts, questions, and experiences with Transformer models in the comments section below. For those seeking to deepen their expertise and accelerate their career in AI, consider expert guidance. Dr. Sundeep Teki, an AI leader with extensive research and product experience at institutions like Oxford, UCL, and companies like Amazon Alexa AI, offers personalized AI coaching. He has a proven track record of helping technical candidates secure roles at top-tier tech companies. You can learn more about his AI expertise, explore his coaching services, and read testimonials from successful mentees.






