During my career in the last decade in analytical roles and working within data, I have seen more organizations understanding the importance of data and embracing collecting and storing data to make decisions to run their business. As result organizations are collecting more data which provides opportunities for analytics and reporting and using data for machine learning applications.
I have worked with technologies that enabled me to help organizations build data products from ingesting data, transforming data, storing data into a data warehouse and inputting into a BI tool, or machine learning model. The tools that I built for these data products are essentially called the Modern Data Stack (MDS).
I will be explaining what the Modern Data Stack is, what are the components to a MDS, what does the MDS mean for a data profession, how did the MDS emerge, how the transformation tool has changed the game, why transforming & modeling data did not work, and how modeling data may have become easier.
Rising Opportunities for the Data Community
The Modern Data Stack is a suite of tools used from easy data integration to storing, transforming data. The goal is to analyze the business data to uncover new areas of opportunity and improve efficiency. The modern data stack's main purpose is to enable teams to scale accordingly and get to speed with the products immediately.
The Modern Data Stack provides organizations the flexibility of their tooling choice.
These are the main components of the Modern Data Stack:
- Data sources — can be data that is captured from your business (sales, customers, product) or application from your website, apps, social media payments — this can be connected to an API.
- Extract and Loading — This layer helps schedule the data to be stored into your data warehouse. This can be source data, which is not ready for reporting.
- Data Warehouse — This is the place to store the source data and also the transformed data ready/near ready for analysis
- Transformation — This is a controlled environment that has instructions to transform, joins multiple data sources, and prepares them for analysis and reporting. The transformation element can also support other features which allow checking for data quality, visuals, how data is modeled (DAGs), and determining how the data is built in the data warehouse. Here is a link to how data is built here using dbt. This can also be linked to a version control environment like Git.
- BI Tools — This is the visualization layer where reports and dashboards can be generated. Depending on the BI tool you can perform lightweight business logic within the data. There are also features for alert and report scheduling.
Over the last 10 years, these are the popular toolings from the image below from when they were first launched.
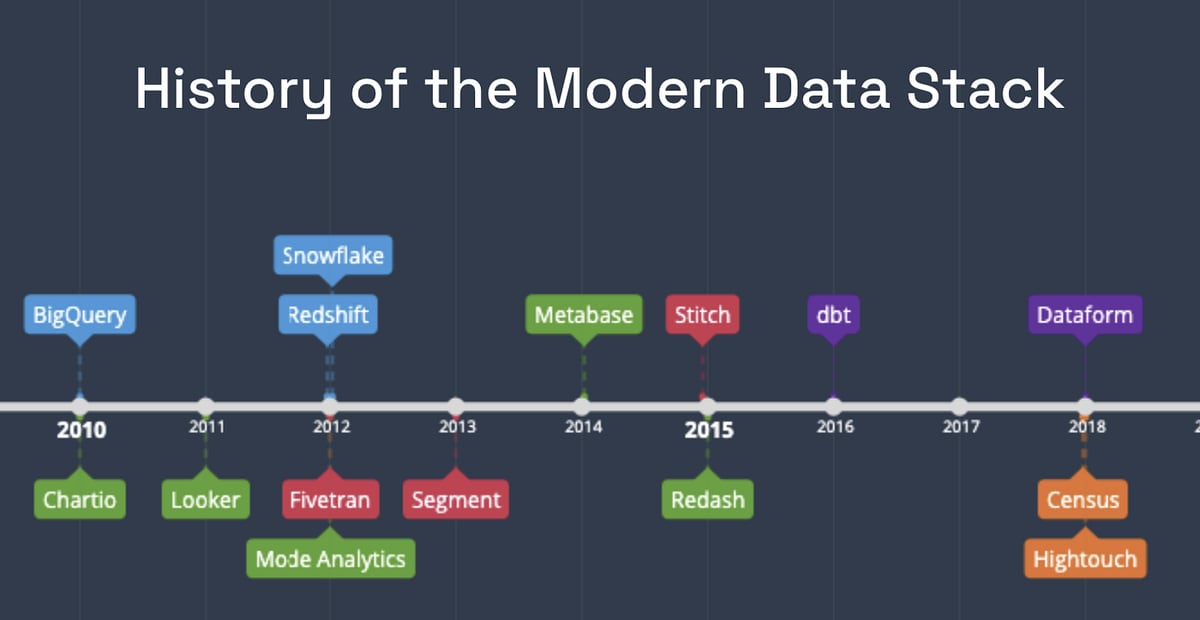
- Blue: Data warehouse
- Red: Ingestion of data
- Purple: Transformation of data
- Green: BI Tools (front layer)
What does the MDS mean as a data profession?
The benefits are that you have the tools and capabilities to support the business quickly, automating workflows, troubleshooting quickly, and abilities to resolve two major issues — data chaos and data breadlines.
Data conflicts are when teams have the same KPIs but different ways they are calculating it, resulting in different results. Data breadlines are when stakeholders are waiting for data teams to answer questions for them when you can resolve by empowering self service BI tools.

A lot of medium-sized and more established organizations have taken advantage of the benefits of the data warehouse and have migrated away from the on-premises servers to the warehouse. However I have witnessed they may not have migrated to the modern data technologies due to reasons like legacy issues, and they may not put this as a priority due to capacity and technical capabilities.
On the other hand, the modern data stack has enabled start-ups to set up their data capabilities quickly and provides them the choice of the tools that suit them. You might be working with different tools due the nature of your team’s needs also where responsibilities are fully defined.
How the Modern Data Stack Emerged?
The MDS has become more popular due to hardwares advancement and availability of cloud computing which has become less expensive for storage, provides parallel computing, and is more secure compared to a classic on-premise data strategy. Cloud computing also allows organisations to scale up and down according to organisations needs.
The wide variety of open source technologies and development have created more opportunities for collecting a wide variety and volume of data.
Why did the old way of transforming & modelling data not work?
When there is a requirement from the business to produce new reporting requirements like measuring new KPIs from a new business revenue stream or new product feature.
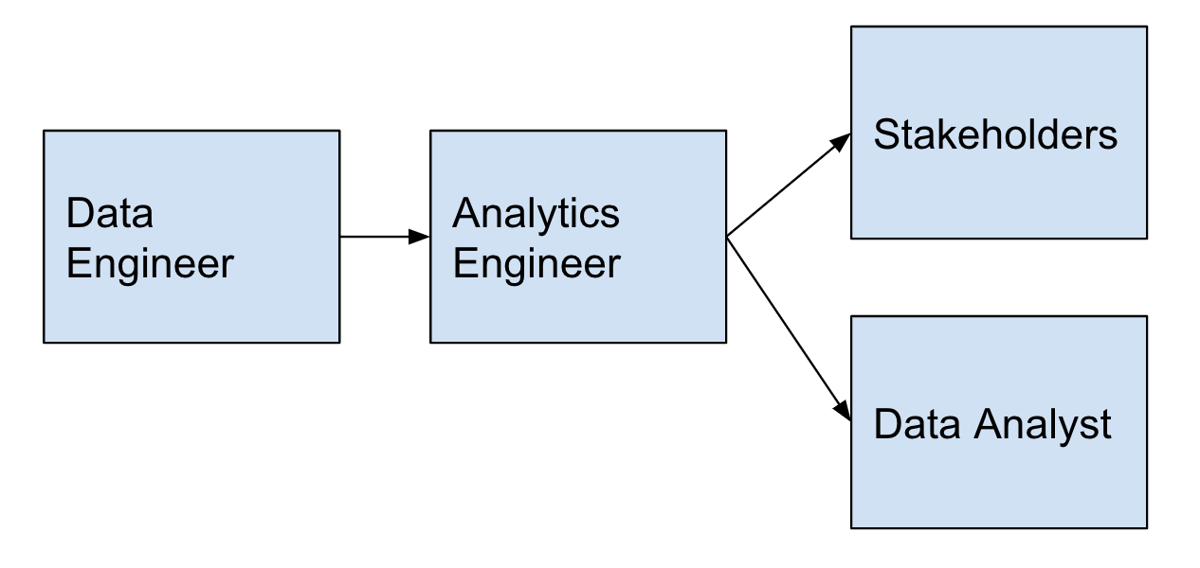
To illustrate this with a simple example with 3 parties of how the process normally works with a data engineer, data analyst, the stakeholders. Note that each organization’s workflow may be different.

There is new tooling which means there is a need to develop new technical skills, take on more responsibilities, work with new best practices and opportunities for new jobs which didn’t exist a few years ago, like Data Engineer and more recently Analytics Engineer, and Product Analysts, and Marketing analysts.
The key challenge in my experience was that it was unclear on whose responsibility it was to model the data with the required business logic and aggregation of the data. Should it be with the data engineers or the data analyst?
I had an experience where the Data Engineer assumed the data can just be modeled in the BI layer by the data analyst to meet the stakeholder's needs. This may achieve the required output however the may have performance issues in the BI tool. Very often data engineers do not understand the technical strain, for modeling the data in the BI tool for the data analyst. For example, the data has to be deleted and completely rebuilt each time and then loaded and performed the aggregations!
Not to mention if the transformation and business logic is stored in the BI tool managed by data analyst — this makes the code difficult to understand and not all BI tools support version control. This adds complexity for maintainability, scaling and future development.
If the responsibility of modeling the data is with the Data Engineers, the process requires a lot of communication on what exactly the Data Analyst was after and confirming with the Data Engineers the requirements are understood. This process makes more sense and is likely a better solution than the above, but when a change of scope is added and it has not been communicated properly it can lead to more complexity and to be understood. Also data transformation can take up the data engineers' capacity when their role should be used to focus on other key areas.
Transformation tooling has been a game-changer!
Traditionally the data engineers undergo the ETL process (Extract, Transform, Load) in the warehouse. With the Modern Data Stack, the data is stored in its source in the warehouse, then transformed and stored again in the warehouse. Remember storing data is cheaper now!
The tool for transformation I’ll be talking about is dbt (data build tool). dbt does the T in ELT (Extract, Load, Transform) processes — it doesn’t extract or load data, but it’s extremely good at transforming data that’s already loaded into your warehouse.
The new way of transforming data created a new role in the data industry called Analytics Engineers in which they can transform data in the warehouses by simply writing select statements. The value of data engineers is to use the collected data and to connect the data to other sources to provide more valuable insights for building data products for the data consumers.
This is store SQL codes which translate business requirements to data requirements. This tool provides power to the traditional data analyst, as they can write SQL and they know the business requirements. This frees more bandwidth for Data engineers to work on other tasks and projects.
dbt also provides ability to write documentation in like a software engineer writing code and adapts best practices. It is also important for analytics engineers to set up testing for data quality, completeness, and having a centralised data strategy for the single source of truth that applies to the business rules. With all that we can have an environment for self-service and reporting.
How is modelling data different and maybe easier?
Older methods of modelling data are becoming less relevant, for example the Kimball technique. Old modelling techniques like the star schema makes it more difficult to maintain code.
It is acceptable to use long wide tables in a Modern Data Stack, compared to star schema — article here by FiveTran that talks about the advantages and performance.
Key Takeaways
The data teams are celebrating because of the huge benefits of the Modern Data Stack, below is a summary of the benefits:
- Reducing data chaos and data breadlines!
- A newer way of working and quicker deployment!
- More controlled development environment — CI/CD, Git version control, schedule of refreshness and readiness of data
I hope you enjoyed my talk and I hope you learned something about the Modern Data Stack. In future talks, we will be talking about the challenges in adapting to the new environment in the data space, and I’ll be sharing my resources with you!







