TLTR
- Understand business priorities, objectives, challenges where AI can help,
- Understand operational, financial, legal, policies constraints to define working context,
- Define success metrics and track them on daily basis, starting from today,
- Understand data, get intimate with data,
- Identify low hanging fruits within top priorities for best value-for-money,
- Otherwise initiate data strategy program,
- Implement empowered product team practices and values that implement the data science practices,
- Enable data driven decision making with trackable strategic metrics,
- Deliver MVP with collectible and actionable feedback loops in place,
- Establish strategy and best practices for IT and operations for early, safe and fast failures,
- Establish values driving emotional safety allowing for experiments and failures,
- Track and analyse feedback loops, iterate and pivot,
- Enable further data-self service to find uncovered data opportunities,
- Establish MLOps practices in order to further empower data science practices,
- Establish FinOps to protect your business and have financial controls as a context for the success metrics,
- Share knowledge and educate,
- Iterate until the success metric reaches the success thresholds or fail fast.
But first, What is AI?
AI stands for artificial intelligence. Artificial means ‘non bio-built’ intelligence. Intelligence means this https://en.wikipedia.org/wiki/Intelligence. The key words from the wikipedia worth stopping by are learning, reasoning, understanding, and critical thinking. I skip these related to ‘self awareness’ as that might trigger a way bigger conversation, I will pick on this in 2025.
Quoting McCarthy:
"AI is the science and engineering of making intelligent machines, especially intelligent computer programs. It is related to the similar task of using computers to understand human intelligence, but AI does not have to confine itself to methods that are biologically observable."
Expanding on this, AI is anything artificial that pretends to have human-like behaviours and reasoning, usually with POC (proof of concept) starting from the levels of worms and iterated over to reach the intelligence of adult(ish) humans, with a way quicker response time (that scales, at least linearly, with the compute spent to run an AI). It can be robots, chatbots, recommending and predicting engines, recognition and translation solutions. I will explore details demystifying AI In another post breaking it down to implementation details, toolsets, mathematical models, ecosystems, practices and crafts. For now the image to the right hints what's coming (and the red cross is not a 404 load-error icon).
For the sake of this very post though let's assume that AI is a very abstract and broad concept and is a cat that can be skinned many ways so to speak. How we go about it depends on many factors related to the specifics of your organisation’s business strategy, data maturity and your specific use-case needs.
AI Product
AI Product development framework
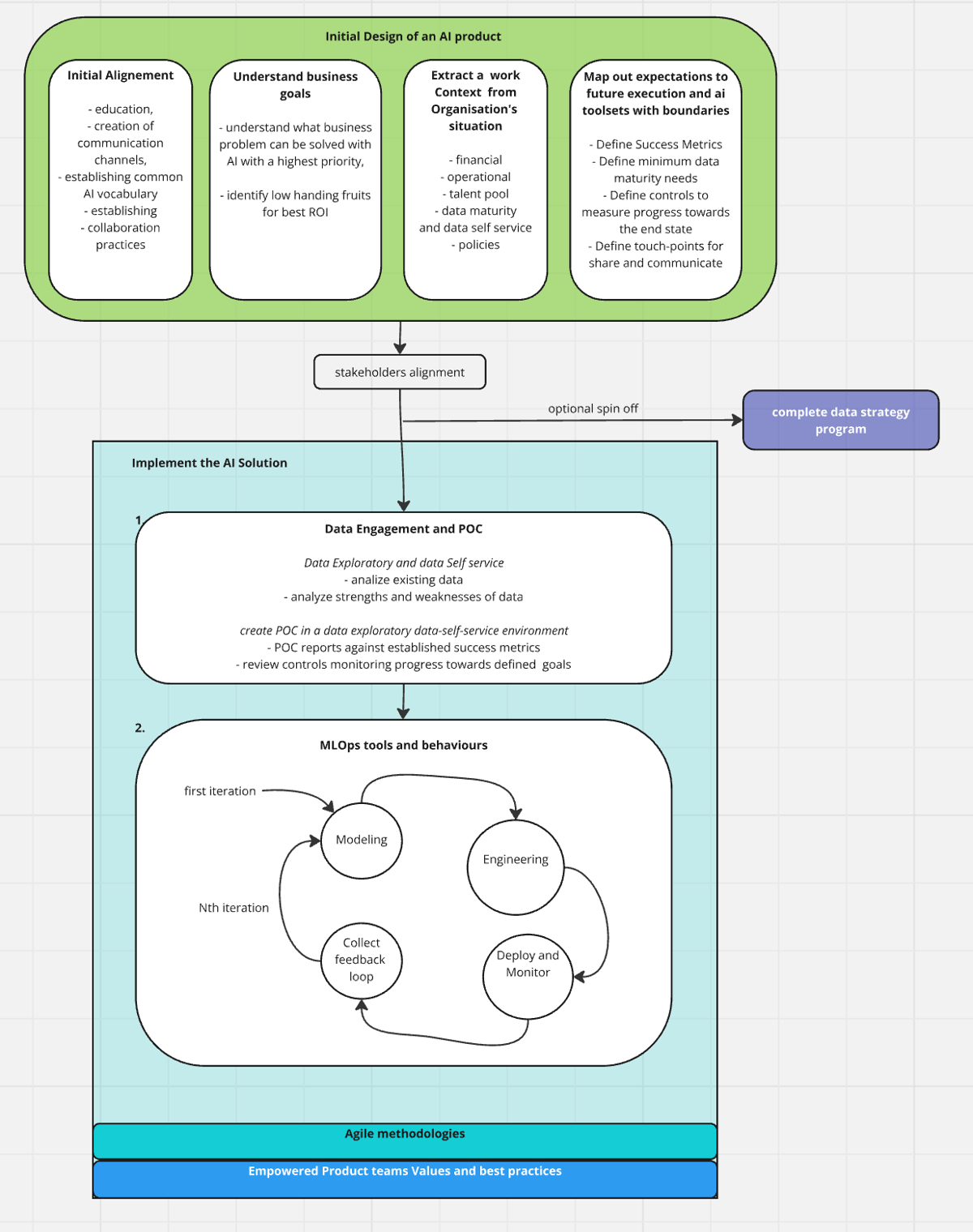
After the initial education and alignment we start with understanding what is needed and why, in other words what are the business objectives and priorities. At this step we establish:
- What are your top business priorities that require data and use of AI?
- How do you measure success for your products and services and how AI can push them up beyond what a traditional software would achieve otherwise?
- What are the main challenges preventing you from achieving those goals, for example do you have necessary data to solve the problem?
This phase is an initial phase to establish direction and perspective for the future work. Worth noting that it’s recommended to prioritise action over extensive planning hence at this stage we do not aim to nail down all the details as there will be best practices and controls in place allowing for iterations and course-correction. We do not need a waterfall type of perfection here.
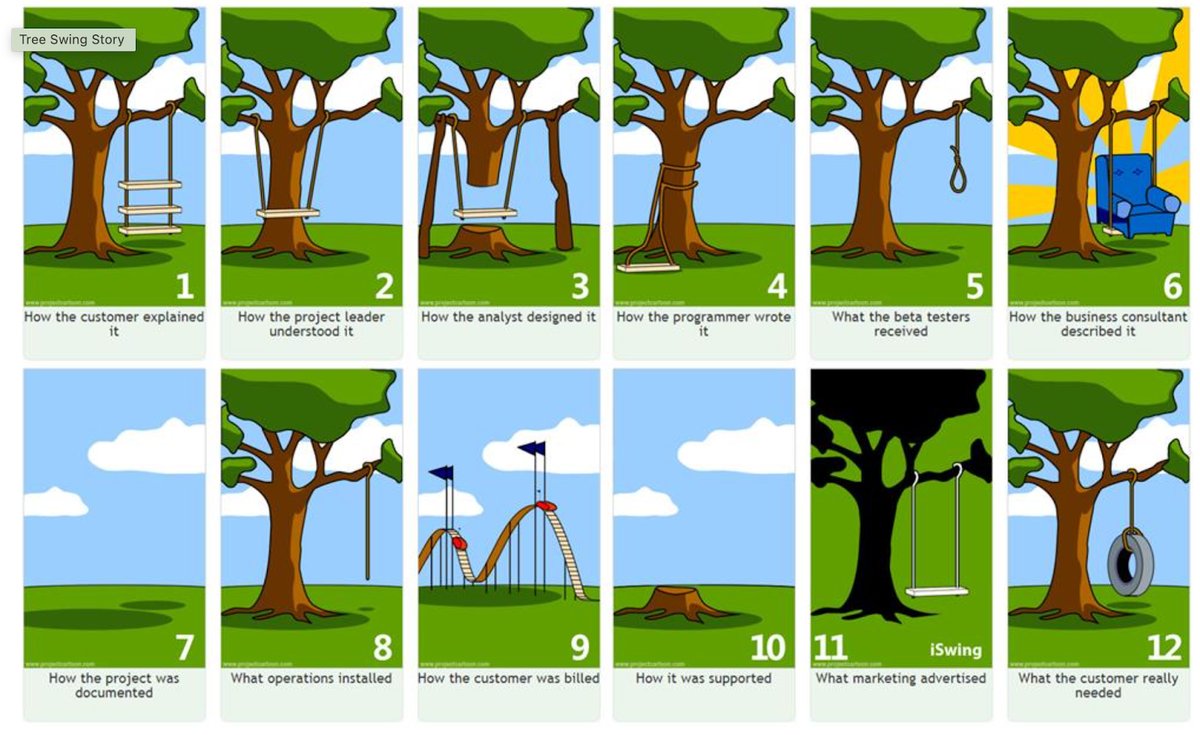
That said, the goal of this exercise is to reduce the risks of ending up in situations like these on the well known old school product management swing sketch. Interestingly it still holds.
Success metrics
What is essential for any data driven project is establishing a success metric that helps level up expectations and track the real progress of the AI project. It allows for every stakeholder to look at results and objective success metrics through the same single pane of glass without much scope for subjective interpretations. It will track the ultimate trends in ROI over time. Trackable success metrics are the controlling element of Values and Practices taken directly from the empowered product teams. This is especially important for AI and data driven solutions where results are not anymore ultimately correct or incorrect, but they rather end up in a grey area hopefully somewhere around good-enough acceptable quality and value thresholds.
I am quite passionate about objective and measurable success metrics. In the end they help with:
- tracking the value for the business over time,
- solving conflicts and eliminate speculations,
- experimenting with objectively scored iterations,
- Reducing costs and protecting from over-engineering,
- Defining and reacting to objective Success and Failure touchpoints.
The beauty of the metrics is that you can incorporate in them whatever matters most. For example conversion rate of a chatbot discussion to a sale divided by the running costs meaning that you only care for the chatbot results as long as the solution is optimised enough to run on low cost computers.
Reviewing the definition of success is equally important. Most likely it will be revised over time as the understanding of the business problem becomes more granular with higher resolution. it could be enough to start with an F1-score but perhaps using advanced quality evaluation frameworks that measure success of LLMs will be necessary.
It’s important to note that If incorporating weighted data from FinOps practices is possible it would be the perspect scenario as not only the outcome would be measured but as well the cost to deliver the very outcome forcing optimisation practices over time.
One more thing to keep in mind, a tiny detail: make sure that the metric is comparable across iterations, and within the same iteration but over time.
My small green inception
I could not help it. Measuring runtime costs and incorporating it in the success metric not only saves on operational costs but also makes sure that your solution is green and eco friendly.
AI and maths toolkits selection and solutioning
Once we have established the product framework and success criteria with tracking metrics we can think about AI solutioning.
Allow me to show off a little bit just to give you a hit of what considerations are taking place behind the scenes. Let's get over it and start with the most exciting and talked about emerging solution patterns - RAG and Agents. Yes, there will be many use-cases and business strategies that require an innovative and modern solution with a find-tuned Large Language Model with embeddings and vector database or knowledge graphs like Neo4J or just postgreSQL (yes!) deployed in a RAG Agent architecture developed with SDKs like LangChain.

And ‘it is sooo cool’ The Internet says.
But with AI these days it is similar to Instagram vs Reality. The image above depicts just the tip of the iceberg and there are high risks for your business if the wrong path is chosen in the beginning. Allow me to repeat: It is essential for your business to select the tools that allow you to deliver AI projects financially efficiently early in an iterative fashion with openness for change and tech adoption at the right time over time.
Given your organisation’s business priorities and data maturity, it might be more optimal, cost efficient and easier to operate to use a supervised-learning model built with a scikit-learn Python that could deliver higher quality for a fraction of costs.
Or perhaps you have BigData and you run natively in the Cloud and need short TTP (time to process) advanced analytics? Then you might need Kafka and scalable, durable and resilient solutions, either serverless or managed Apache Hadoop ecosystems like Spark and Flink combined with data sources like Kafka and S3 and OLAP warehousing.
For contrast, it could very well be that all that is needed is accurate actionable reports, improved Business Intelligence, data analysis, data self-service and data exploratory capabilities.
Hence the above, early in the process we will aim to get intimate with your data in order to understand, with confidence, where the value is, where the risks are (like biases, silos) and where to focus our efforts for highest ROI. The focus will be placed on low hanging fruits to deliver AI solutions quickly so that the multi-iteration cycle with user feedback loops can start straight away. Thanks to implementing data intimacy early in the game the selection of the appropriate tech stacks and AI toolkits will be more accurate with less risks more aligned with the context of the client’s business.
At this point production becomes one with the product design cycle.
AI use cases consideration
Thanks to the data exploratory phase and interactive experiments it will be easier to identify where it is best to apply AI and in what form, all within quality requirements and the established data maturity. The goal here is to select the right AI toolsets that will match best your inference requirements, running and operational costs.
There is hundreds of applications of AI emerging every day, there are indicators that AI could solve your business problems that usually is described with use of some magic words from this vocabulary:
- Guesstimate,
- Predict,
- Generate,
- Approximate,
- Uncommon/Anomaly,
- Similarity,
- Cluster/Relate,
- Recognize,
- Recommend/Filter out,
- transform/translate.
AI toolset selection will depend on your business and we will consider the entire landscape of AI:
- Predict the unknown future based on historical data, with supervised and unsupervised learning? Future foreseeing! - who does not want that? This will help you position your business in the best possible strategic position. This will improve your client experience too. For example financial markets prediction or pandemic modelling, failure prediction etc.
- Classify data, images, video and any other type of content to automate work that in the past needed potentially large teams. For example cyber attacks detection triaged by AI rather than security experts at SOC or customer service ticket classification. Creates large savings and reduces talent-pool access problems.
- Sentiment analysis and NLP has many applications including:
- churn prediction,
- document classification and summarisation,
- data normalisation,
- text-2-voice,
- Clustering and similarities with distance functions to deliver use cases like
- market segmentation,
- social network analysis,
- search result grouping,
- medical imaging,
- image segmentation,
- anomaly detection.
- Content creation and specialised advisors with RAG (Retrieval-augmented-generation) and vector searches. Use of LLM can eliminate manual tasks that do not need creativity or It can help accessing expertise that has premium cost (i.e. legal expertise and advice, software engineering coding expertise, sickness diagnosis).
Selection of the correct toolset will depend as well on the data volume and quality available.
- Are there data silos and can it be correlated?
- Is the data labelled and can it be used for supervised learning?
- Is the data normalised, structured and standardised to create future ready solutions or is it vendor specific?
- Volume of data? BigData? See what is suggested here. Btw: I love the tough-luck option. I read it as: look for more advanced strategies like off the shelf models, use na LLM and fine tune it instead, use open-source data sources, buy data, create synthetic data sets.
Optimising the solution for the best outcomes within established constraints
As briefly covered above the AI solution is designed for specific needs and context created by the client such as:
- Expected outcomes,
- data at hand,
- Operation models,
- Financial model and financial constraints,
- Confidentiality vs openness Policies,
- skill sets available.
The client’s context creates constraints that force the product definition to gain more edges. At the same time the power of AI is its flexibility, adaptability and generalisation, capability of working with the unknown. It can deliver, via many different AI means, the same set of AI applicable use cases. The chosen solution will drive different quality of the outcomes, running costs, operational challenges, necessity for a data strategy program.
Established quality thresholds will depend on your priorities, i.e. will you prioritise cost efficiency over accuracy over recall (coverage of all the possible true-positives for the price of higher volume false-positives).
It’s a balancing act to deliver the most optimum solution within the constraints identified for your organisation like budget, data available, operational practices, skill set available and type of the operating actors and users.
Data Strategy
On the AI journey it might be necessary to work together on a detailed data strategy program and there will be another post elaborating on it in detail. At this point It’s important to note that the execution of a data strategy program should always be an enabler in a non-blocking fashion so that first AI solutions are delivered ASAP rather than wait for the outcomes of the data-strategy initiatives.
The End-to-End Data Strategy program will consist of the following steps and will be covered in details in another post.
- understanding your business objectives,
- establish and score your current state,
- define end-goal state and map success metrics to measure progression towards the desired end state,
- establish controls that will drive behaviours towards the desired end state,
- design and create integrated solutions,
- Scale the solutions and the talent pool.
Data-strategy analysis might conclude a full-blown solution built with help of vendors like Databricks and Snowflake but more often would prioritise small tweaks in order to enable some most valuable AI readiness as early as possible.
Reputation
Partner’s reputation is his brand and wealth. Values like open and honest collaboration with our clients and if we see that the highest ROI lies in a classic heuristic-based solution we will recommend it. In turn it will reduce costs, complexity and ease the talent pool challenges. This approach will protect you from the emerging reputation problems related to AI washing or AI solutions with a very low fidelity, quality and accuracy.
Similarly while working on an AI solution there will be the best practices discussed already combined with Post-Development Testing and Validation with measurable feedback loops. Combining these practices with elastic cloud native capabilities like canary deployments and A-B testing or blue-green deployments alongside with frequent iterations will mitigate reputation risks even further.
That said, it is understood very well that one often needs to start with a pinch of hope within understood risks and invest in AI to just to start exploring the opportunities beyond the known horizon. In these situations, we advise the iterative approach from empowered product teams, review results with a client on recruiting basis, pivot if needed and allow for failure in a safe space both culturally and technologically.
It is extremely important to ensure that values and practices will drive and support Curiosity.
With our best practices we will make sure that the failure happens yet it happens early to reduce the risks and to use this opportunity to gather data that will fuel more precise product development.
Operations, Finances and Policies
As hinted before, what matters too is operational practices and financial models as well your value based policies. If your organisation is already Elastic Cloud Native in an opex financial model, we will recommend a different solution than for an organisation with a bare-metal data centre built for purpose with a high capex footprint. We will make sure that the offered solution will be compatible with your existing operations and business models. It’s crucial as well that our solution will be aligned with your Policies especially related to openness, confidentiality and data access controls.
MLOps
There are plenty of MLOps solutions on the market, some open source (MLFlow or BentoML), some commercial and some vendor specific (i.e. SageMaker from AWS). There will be a moment in time when we will recommend the best suit for your IT capabilities. That said, these are only implementation details that can be supported by many tools. What is more important is how the teams work and operate. This is where we can help and offer a mature AI Product team with right management, operational practices, values and culture. It’s essential to understand that the Software Development practices, behaviours, SDLC are not sufficient for Data driven projects. THe behaviour of a team and its approach to risk can either make an AI project Successful or completely destroy.
It’s essential to change the behaviour of a software team to become a fully self sufficient Data Science Empowered Product team. This needs changes in management and operations especially to:
- Allow for data-science where Science means experiments,
- Experiments means iterations and results comparison, therefore:
- Allow for quick iterations,
- Allow for fail-fast (fast in a safe fashion),
- Manage the risk of failures with elasticity and cloud native deployment strategies like ab testing, blue-green deployments and canary deployments,
- Measure and compare the experiment results,
- Collect Feedback-loop essential,
- Create financial context with FinOps practices
FinOps
There is beauty in the elasticity of the native cloud, you can solve any performance problem with more resources thrown at them. The same applies to AI and ML solutions - the more data you throw at it the more compute you need to process the data, the higher compute bills.
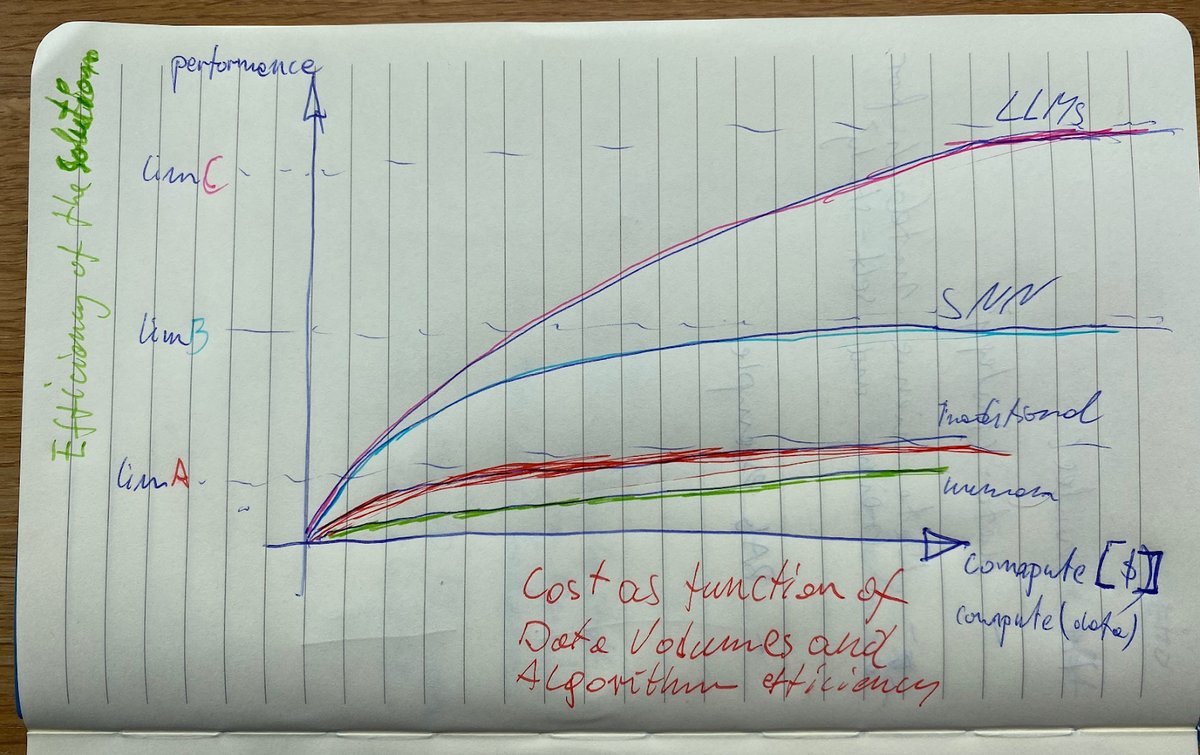
With finOps you make sure you stop optimising the AI solution when it’s not worth it anymore. You can see on the hand drawing above that there is a limit that would be very costly to reach , with very small gain for a very large cost. There is a logarithmic correlation between effectiveness and precision of your models and volume of data and compute allocated to your solution. In the early stages of the AI projects the gains from compute will be significant therefore worth it’s bills, later on you might end up fighting for an extra 1% of precision for doubling the costs of compute costs. Your business will need to decide when to stop. FinOps will be responsible for monitoring, reporting and alerting the costs of your solution. Hopefully your cusses metrics will incorporate the input from FinOps metrics.
Conclusion
The main message I tried to drive home is that:
- Data driven decision making is essential hence a clear definition of success is paramount,
- Collaboration, iteration and experimenting with feedback loops over hard processes,
- deliver on the desired outcomes, rather than focusing on using specific tools. Select the AI Tool according to the needs. Don't kill a fly with a jackhammer.
- Pragmatic approach focused on the success of ours and your clients tracked with defined metrics within the context extracted from the current situation of a client,
- Open for change and pivot quickly,
- AI is more complex than it seems. it’s a good thing as focusing on details allows to deliver amazing results within cost constraints what offers a competitive advanced,
- Safety for failure, psychological and technological, as an enabler for rapid development,
- Share the knowledge, educate, eliminate the high bus factors.
Big thanks to Paweł Wyparło and Fiona Strasser from Montrose Software for the second pair of eyes and very objective and honest feedback.
Please reach me out with any sort of criticism and broader input at [email protected]
Have a lovely week!






