1. Conceptual Foundations: From Prompt to System
The discourse surrounding Large Language Models (LLMs) has historically been dominated by model scale and prompt design. However, as the capabilities of foundational models begin to plateau, the critical differentiator for building effective, reliable, and "magical" AI applications has shifted from the model itself to the information ecosystem in which it operates. This section establishes the fundamental paradigm shift from the tactical act of writing prompts to the strategic discipline of engineering context, grounding the practitioner in the core principles that motivate this evolution.
1.1. Defining the Paradigm: The Rise of Context Engineering
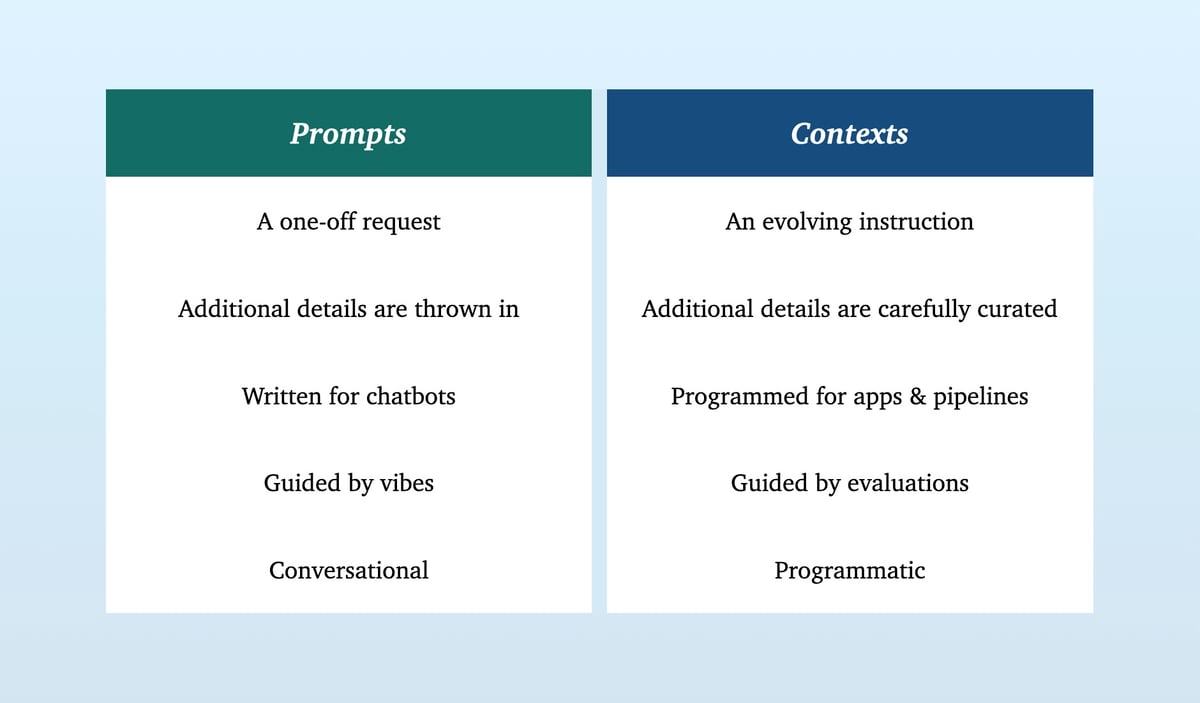
Context Engineering is the discipline of designing, building, and optimizing the dynamic information ecosystem provided to an AI model to perform a task. It represents a fundamental evolution from the stateless, single-turn world of prompt engineering to the stateful, multi-turn environment of sophisticated AI systems. While prompt engineering focuses on crafting the perfect instruction, context engineering architects the entire world of knowledge the model needs to interpret that instruction correctly and act upon it effectively.
This engineered context is a composite of multiple information streams, including but not limited to:
System Instructions: High-level directives that define the AI's persona, role, and constraints.
User State: Implicit and explicit information about the user, such as their role, preferences, and past interactions.
Retrieved Knowledge: Dynamically fetched documents, data, or facts from external knowledge bases, which forms the core of Retrieval-Augmented Generation (RAG).
Tool and API Schemas: Definitions of external functions the model can call to interact with the world.
Environmental Signals: Real-time data about the operational environment, such as recent file changes, system logs, or open IDE tabs for a coding assistant.
The central argument is that "context is king" and serves as the primary differentiator between a fragile demo and a robust, production-grade AI product. The distinction between these two disciplines is not merely semantic; it reflects a deep architectural and philosophical shift in how AI applications are conceived and built.
1.2. The "Context is King" Paradigm: Why World-Class Models Underperform
A persistent and uncomfortable truth in applied AI is that the quality of the underlying model is often secondary to the quality of the context it receives. Many teams invest enormous resources in swapping out one state-of-the-art LLM for another, only to see marginal improvements. The reason is that even the most powerful models fail when they are fed an incomplete or inaccurate view of the world.
The core limitation of LLMs is their reliance on parametric knowledge - the information encoded in their weights during training. This knowledge is inherently static, non-attributable, and lacks access to private, real-time, or domain-specific information. When a model is asked a question that requires information beyond its training cut-off date or about a proprietary enterprise database, it is forced to either refuse the query or, more dangerously, "hallucinate" a plausible-sounding but incorrect answer.
Context Engineering directly addresses this fundamental gap. It is the mechanism for providing the necessary grounding to ensure factual accuracy, relevance, and personalization.
Consider a simple task: scheduling an email. A prompt like "Email Jim and find a time to meet next week" sent to a generic LLM will yield a generic, unhelpful draft. However, a system built with context engineering principles would first construct a "contextual snapshot". This snapshot would include:
The user's calendar availability.
The user's typical meeting preferences (e.g., mornings, 30-minute slots).
The history of interactions with "Jim."
The user's preferred tone ("be concise, decisive, warm").
By feeding this rich context to the same LLM, the system can generate a "magical" and immediately useful output, such as: "Hey Jim! Tomorrow's packed on my end, back-to-back all day. Thursday AM free if that works for you? Sent an invite, lmk if it works". The model did not get "smarter"; its environment did. This illustrates the core principle: the value is unlocked not by changing the model, but by fixing the context.
1.3. The "Context-as-a-Compiler" Analogy: A New Mental Model for Development
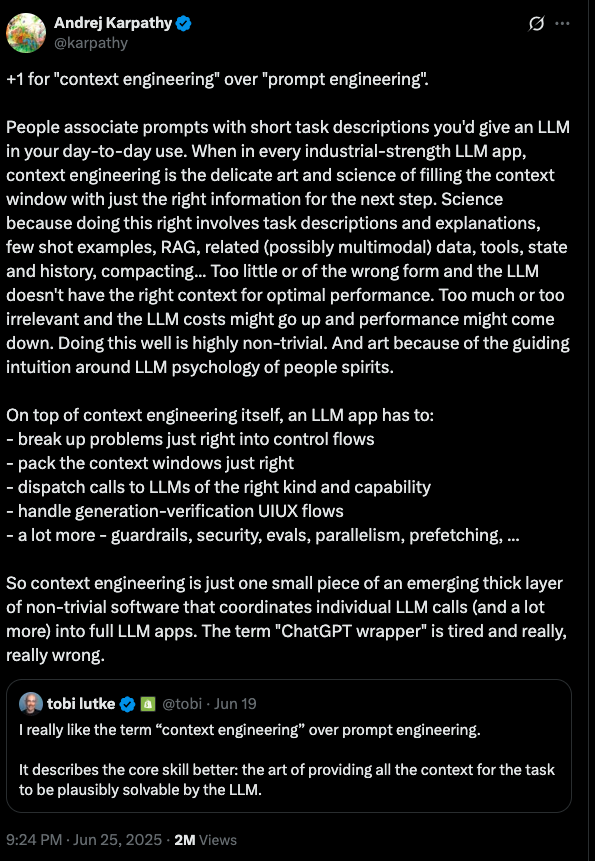
A powerful mental model for understanding this new paradigm is the "Context-as-a-Compiler" analogy, a concept discussed by leading researchers like Andrej Karpathy. This model reframes the LLM as a new kind of compiler that translates a high-level, often ambiguous language (human intent expressed in natural language) into a low-level, executable output (e.g., code, API calls, structured JSON).
In this analogy, the prompt is not just a question; it is the source code. The context is everything else the compiler needs to produce a correct, non-hallucinated binary. This includes the equivalent of:
Libraries and Dependencies: Retrieved documents and knowledge sources.
Type Definitions and Interfaces: API schemas and tool descriptions.
Environmental Variables: User state and real-time system information.
The goal of context engineering, therefore, is to make the compilation process as deterministic and reliable as possible. A traditional C++ compiler will fail if a function is called without being declared; similarly, an LLM will "hallucinate" if it is asked to operate on information it does not have. Context engineering is the practice of providing all the necessary declarations and definitions within the context window to constrain the LLM's stochastic nature and guide it toward the correct output.
This analogy also illuminates a fundamental shift in the developer workflow. When code generated by a tool like GitHub Copilot is wrong, developers often do not debug the incorrect Python code directly. Instead, they "fiddle with the prompt" or adjust the surrounding code until the generation is correct. In the compiler analogy, this is equivalent to modifying the source code and its dependencies. The context is the new debuggable surface. This implies that the primary skill for the AI-native developer is not just writing the final artifact (the code) but curating and structuring the context that generates it. The development environment of the future may evolve into a "context IDE," where developers spend more time managing data sources, retrieval strategies, and agentic workflows than editing lines of code. The rise of "vibe coding" - describing the "vibe" of what is needed and letting the AI handle the implementation - is a direct consequence of this new layer of abstraction.
However, the analogy has its limits. Unlike a traditional compiler, which is a deterministic tool, an LLM is a stochastic system that can creatively resolve ambiguity. This is both its greatest strength and its most significant weakness. While a compiler will throw an error for ambiguous code, an LLM will make its best guess, which can lead to unexpected (and sometimes brilliant, sometimes disastrous) results. The art of context engineering lies in providing enough structure to ensure reliability while leaving just enough room for the model's powerful generative capabilities to shine.
2. The Architectural Blueprint of Context-Aware Systems
Moving from conceptual foundations to technical implementation, this section details the architectural patterns and components that form the backbone of modern context-engineered systems. These blueprints provide the "how" that enables the "why" discussed previously, focusing on the core mechanisms for grounding LLMs in external knowledge.
2.1. The Foundational Pattern: Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is the cornerstone pattern of context engineering. Introduced in the seminal 2020 paper by Lewis et al., RAG was designed to combine the strengths of parametric memory (knowledge stored in model weights) and non-parametric memory (an external knowledge base). It directly addresses the static knowledge problem by allowing an LLM to "look up" relevant information before generating a response.
The standard RAG process consists of three primary stages :
Indexing: An external corpus of documents (e.g., Wikipedia, company wikis, product documentation) is pre-processed. The documents are broken down into smaller, manageable "chunks." Each chunk is then passed through an embedding model (e.g., a sentence-transformer) to create a high-dimensional vector representation. These vectors, which capture the semantic meaning of the text, are stored in a specialized vector database optimized for efficient similarity search.
Retrieval: When a user submits a query, that query is also converted into a vector embedding using the same model. The system then performs a nearest-neighbor search in the vector database to find the document chunks whose embeddings are most semantically similar to the query embedding. The top-k most relevant chunks are retrieved.
Augmentation and Generation: The retrieved document chunks are concatenated with the original user query and a system prompt. This augmented prompt is then fed to the LLM. The model uses the provided context to generate a response that is grounded in the retrieved facts, significantly reducing hallucinations and improving accuracy.
The formal innovation of the RAG paper was to frame this process as a probabilistic model that could be trained end-to-end.
2.2. The Critical Decision: RAG vs. Fine-Tuning
A primary strategic decision facing any team building with LLMs is whether to use RAG, fine-tuning, or both. These methods address different problems and have distinct trade-offs in terms of cost, complexity, and capability. Choosing the correct path is crucial for project success.
RAG is fundamentally about providing knowledge. It excels when an application must operate on external, dynamic, or proprietary information. Its key strengths are providing up-to-date responses, reducing factual hallucinations by grounding outputs in source material, and offering explainability by citing sources. Implementation is generally less complex and cheaper than fine-tuning, as it primarily involves data pipelines and architecture rather than GPU-intensive training runs.
Fine-tuning is fundamentally about teaching a skill or behavior. It modifies the model's weights to adapt its style, tone, or format, or to make it an expert in a highly specialized domain with its own jargon and reasoning patterns. It is best for embedding static knowledge that is required consistently across many tasks, or for altering the fundamental way the model responds.
The consensus among practitioners is to start with RAG by default. It is faster, cheaper, and safer for most use cases involving factual knowledge. Fine-tuning should only be considered when RAG proves insufficient to achieve the desired behavior or when the task is purely about style and not knowledge.
2.3. The Hybrid Approach: The Best of Both Worlds
While RAG and fine-tuning are often presented as an either/or choice, the most sophisticated systems frequently employ a hybrid approach to achieve performance that neither method can reach in isolation. This strategy recognizes that the two methods are complementary: RAG provides the facts, while fine-tuning teaches the skill of using those facts.
The standard RAG approach relies on a general-purpose base model to synthesize an answer from the retrieved context. However, this base model may not be optimized for this specific task. It might struggle to identify the most salient points in the context, ignore contradictory evidence, or fail to structure the output in the desired format.
A hybrid approach addresses this by fine-tuning the generator model specifically to be a better RAG component. The fine-tuning dataset in this case would not consist of just questions and answers. Instead, each example would be a triplet of (query, retrieved_context, ideal_answer). The goal of this fine-tuning is not to bake the knowledge from the retrieved_context into the model's weights. Rather, it is to teach the model the skill of faithfully synthesizing a high-quality answer from whatever context it is given.
This fine-tuning can teach the model to:
Pay closer attention to the provided context and ignore its own parametric knowledge.
Handle noisy or irrelevant retrieved documents more gracefully.
Adhere to a specific output format (e.g., "Answer the question and then provide a list of supporting quotes from the context").
Synthesize information from multiple retrieved chunks.
The optimal architecture for many complex enterprise applications is therefore a model that has been fine-tuned for "contextual reasoning and synthesis," coupled with a powerful and dynamic RAG pipeline. This allows the system to learn the desired style and structure via fine-tuning, while dynamically populating its responses with up-to-date facts from RAG.
3. Advanced Frontiers and State-of-the-Art Techniques (2025)
The field of Context Engineering is evolving at a breathtaking pace. Beyond the foundational RAG pattern, a new frontier of autonomous, efficient, and structured techniques is emerging. This section explores the state-of-the-art developments that are defining production-grade AI systems in 2025 and beyond.
3.1. The Agentic Leap: From Static Pipelines to Autonomous Systems
The most significant evolution in context engineering is the shift from linear RAG pipelines to dynamic, autonomous systems known as Agentic RAG. While traditional RAG follows a fixed Retrieve -> Augment -> Generate sequence, Agentic RAG embeds this process within a reasoning loop run by an autonomous agent. This transforms the system from a simple information processor into an adaptive problem-solver.
Agentic RAG systems are built upon a set of core design patterns that enable autonomous behavior :
Planning: The agent first breaks down a complex, multi-step user query into a sequence of smaller, executable tasks. For example, the query "Compare the Q1 financial performance of our company with our top two competitors" might be decomposed into: (1) Identify our company's top two competitors, (2) Find our company's Q1 earnings report, (3) Find competitor A's Q1 report, (4) Find competitor B's Q1 report, (5) Synthesize the key metrics and generate a comparison table.
Tool Use: Agents are given access to a suite of external tools, which can range from simple web search APIs to complex code interpreters or internal database query engines. The agent's planning step determines which tools to use and in what order to gather the necessary information.
Reflection: After executing a step or generating a piece of information, the agent can pause to self-critique its output. It might ask itself: "Is this answer complete? Does it directly address the user's query? Is the source reliable?" This reflective loop allows for iterative refinement and error correction, leading to a much higher quality final response.
Multi-Agent Collaboration: For highly complex workflows, a single agent may be insufficient. Multi-agent systems distribute responsibilities across a team of specialized agents. For instance, a "Manager" agent might perform the initial planning and delegate sub-tasks to a "Web Search" agent, a "Database" agent, and a "Summarization" agent. These agents collaborate to fulfill the request, passing information back and forth before the final answer is composed.
This evolution from static to agentic systems represents a significant leap in capability, enabling applications to handle ambiguity, perform multi-hop reasoning, and interact with the world in a far more sophisticated manner.
3.2. Taming the Beast: Context Compression and Filtering in Million-Token Windows
As LLMs with context windows of one million tokens or more become commonplace, a new set of challenges has emerged. While vast context windows are powerful, they introduce significant issues with cost, latency, and the "needle-in-a-haystack" problem, where models struggle to identify and use relevant information buried within a sea of irrelevant text. Simply stuffing more documents into the prompt is not a viable strategy.
The solution lies in intelligent context compression and filtering. The state-of-the-art in this area has moved beyond simple summarization to more sophisticated, query-aware techniques.
A leading example is the Sentinel framework, proposed in May 2025. Sentinel offers a lightweight yet highly effective method for compressing retrieved context before it is passed to the main LLM.
The core mechanism of Sentinel is both clever and efficient :
Reframing the Problem: Instead of training a large, dedicated model to perform compression (which is expensive and not portable), Sentinel reframes compression as an attention-based understanding task.
Using a Proxy Model: It takes a small, off-the-shelf "proxy" LLM (e.g., a 0.5B parameter model). The retrieved documents and the user query are fed into this small model.
Probing Attention: Sentinel does not care about the text the proxy model generates. Instead, it probes the internal decoder attention scores. Specifically, it looks at the attention patterns from the final generated token back to the input sentences. The hypothesis, which holds up empirically, is that sentences highly relevant to the query will receive more attention from the model as it prepares to generate an answer.
Lightweight Classification: These attention signals are extracted as feature vectors for each sentence. A very simple, lightweight classifier (a logistic regression model) is trained to map these attention features to a relevance score.
Filtering: At inference time, sentences are scored for relevance using this proxy model and classifier. Only the top-scoring sentences are selected and passed to the large, expensive generator LLM.
The key advantage of Sentinel is its efficiency and portability. The central finding is that query-context relevance signals are remarkably consistent across different model scales. This means a tiny 0.5B model can act as an effective proxy for a massive 70B model in determining what context is important. On the LongBench benchmark, Sentinel can achieve up to 5x context compression while matching the question-answering performance of systems that use the full, uncompressed context, and it outperforms much larger and more complex compression models.
3.3. Beyond Text: Graph RAG and Structured Knowledge
The majority of RAG implementations operate on unstructured text. However, a great deal of high-value enterprise knowledge is structured, residing in databases or knowledge graphs. Graph RAG is an emerging frontier that integrates these structured knowledge sources into the retrieval process.
Instead of retrieving disconnected chunks of text, Graph RAG traverses a knowledge graph to retrieve interconnected entities and their relationships. This allows the system to perform complex, multi-hop reasoning that would be nearly impossible with text-based retrieval alone. For example, to answer "Which customers in Germany are using a product that relies on a component from a supplier who recently had a security breach?", a Graph RAG system could traverse the graph from the breached supplier to the affected components, to the products using those components, and finally to the customers who have purchased those products in Germany.
This approach enriches the context provided to the LLM with a structured understanding of how different pieces of information relate to one another, unlocking a more profound level of reasoning and analysis.
4. Practical Implementation and Performance
Bringing these advanced concepts into production requires a focus on real-world applications, robust measurement, and disciplined engineering practices. This final section of the technical guide provides a pragmatic roadmap for implementing, benchmarking, and maintaining high-performance, context-aware systems.
4.1. Context Engineering in the Wild: Industry Use Cases
Context engineering is not a theoretical exercise; it is the driving force behind a new generation of AI applications across numerous industries.
Developer Platforms & Agentic Coding: The next evolution of coding assistants is moving beyond simple autocomplete. Systems are being built that have full context of an entire codebase, integrating with Language Server Protocols (LSP) to understand type errors, parsing production logs to identify bugs, and reading recent commits to maintain coding style. These agentic systems can autonomously write code, create pull requests, and even debug issues based on a rich, real-time understanding of the development environment.
Enterprise Knowledge Federation: Enterprises struggle with knowledge fragmented across countless silos: Confluence, Jira, SharePoint, Slack, CRMs, and various databases. Context engineering provides the architecture to unify these disparate sources. An enterprise AI assistant can use a multi-agent RAG system to query a Confluence page, pull a ticket status from Jira, and retrieve customer data from a CRM to answer a complex query, presenting a single, unified, and trustworthy response.
Hyper-Personalization: In sectors like e-commerce, healthcare, and finance, deep context is enabling unprecedented levels of personalization. A financial advisor bot can provide tailored advice by accessing a user's entire portfolio, their stated risk tolerance, and real-time market data. A healthcare assistant can offer more accurate guidance by considering a patient's full medical history, recent lab results, and even data from wearable devices.
4.2. Measuring What Matters: A Hybrid Benchmarking Framework
To build and maintain high-performing systems, one must measure what matters. However, teams often fall into the trap of focusing on a narrow set of metrics. An AI team might obsess over RAG evaluation scores (like faithfulness and relevance) while ignoring a slow and brittle deployment pipeline. Conversely, a platform engineering team might optimize for DORA metrics like cycle time while deploying a model that frequently hallucinates.
The performance of a context-aware system is a function of both its AI quality and the engineering velocity that supports it. A truly elite team must track both. This requires a unified "Context Engineering Balanced Scorecard" that bridges the worlds of MLOps and DevOps, providing a holistic view of system health and performance.
The logic is straightforward: a model with perfect accuracy is useless if it takes three months to deploy an update. A system with daily deployments is a liability if each deployment introduces new factual errors. Success requires excellence on both fronts.
4.3. Best Practices for Production-Grade Context Pipelines
Distilling insights from across the research and practitioner landscape, a set of clear best practices emerges for building robust, production-grade context engineering systems.
Treat Context as a Product: Your knowledge base is not a static asset; it is a living product. Implement version control, automated quality checks, monitoring for data drift, and feedback loops to continuously improve the quality of your context sources.
Start with RAG, Not Fine-Tuning: For any task involving external knowledge, RAG should be the default starting point. It is cheaper, faster, and more transparent. Only explore fine-tuning if RAG proves insufficient to teach a specific behavior or style.
Structure Your Prompts for Clarity: The structure of the final prompt matters. Place high-level instructions at the very beginning. Use clear separators like ### or """ to distinguish between instructions, context, and the user query. For very long context tasks, place the large documents at the top of the prompt, followed by the specific question or instruction, as this helps the model focus on the task after ingesting the information.
Leverage In-Context Learning: Guide the model's behavior by providing a few high-quality examples (few-shot learning) directly in the prompt. These examples should be varied, cover different scenarios, and use a consistent format to help the model recognize the desired pattern.
Iterate Relentlessly: Building a great context-aware system is an iterative process of experimentation. Continuously test different chunking strategies, embedding models, retrieval methods, and prompt structures. Measure performance using a balanced scorecard and refine your approach based on empirical data.
5. Failures of Context
For a deeper dive into the various failure modes of context understanding, I recommend Drew Breunig's excellent blog in which he highlights 4 diverse challenges of long context -
Context Poisoning: When a hallucination or other error makes it into the context, where it is repeatedly referenced.
Context Distraction: When a context grows so long that the model over-focuses on the context, neglecting what it learned during training.
Context Confusion: When superfluous information in the context is used by the model to generate a low-quality response.
Context Clash: When you accrue new information and tools in your context that conflicts with other information in the prompt.
He also shares potential solutions to effective context management -
RAG: Selectively adding relevant information to help the LLM generate a better response
Tool Loadout: Selecting only relevant tool definitions to add to your context
Context Quarantine: Isolating contexts in their own dedicated threads
Context Pruning: Removing irrelevant or otherwise unneeded information from the context
Context Summarization: Boiling down an accrued context into a condensed summary
Context Offloading: Storing information outside the LLM's context, usually via a tool that stores and manages the data
6. Resources
https://blog.langchain.com/the-rise-of-context-engineering/
https://www.dbreunig.com/2025/06/26/how-to-fix-your-context.html
https://www.dbreunig.com/2025/06/22/how-contexts-fail-and-how-to-fix-them.html
https://boristane.com/blog/context-engineering/
https://x.com/karpathy/status/1937902205765607626
Lewis et al. (2020), "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks"
Singh et al. (2025), "Agentic Retrieval-Augmented Generation: A Survey"
Zhang et al. (2025), "Sentinel: Attention Probing."






