Codebase standards
You have a project idea and a minimum of planning ready; Creating a repository to store and manage your repository is not enough to officially kick off your project. Instead, since day 0, before letting others contribute to your project, you have to configure, define, set up and document at least the following standards:
- GitFlow
- Branch hierarchy
- Branch protection rules
- Dependencies analysis
- Testing coverage analysis
- Code quality checks
- Continuous Integrations pipelines
- Merge Request Review requests
- Bug report strategy
GitFlow
A gitFlow, is a defined strategy for managing Git branches, commit standards and Merge request procedures.
Common GitFlow tends to identify two different types of branches:
- Feature: for the development of a new feature
- HotFix: for the fixing of a bug (or overall performance improvements)
The nature of the git branches convention that I adopt allows me to identify quickly:
- The developer
- Nature of the task
- Issue (or Task) id.
- And the overall goal of the branch (short description).
Suppose that developer Davide Pollicino, having Github username omonimus1, is in charge of developing the sign-up process assigned to him by the task with id 1. The branch created will use the following name:
omonimus1/feature/#1-implement-sign-up-process
Now that a first branch naming convention is set, it is time to define the message commit standards. Any commit message must contain the id of the issue correlated to (at any point).
Following the example given above, my commit message could be:
“#1: Adds sign-up functionality”
This naming convention, at least on Github and Gitlab, allows to visualise any commit associated with the task, as shown in the picture below:
Visualisation of commits related to the task
There is a second school of toughts which is growing in popularity, preferring Trunk-based development than standardised Gitflow.
Branch hierarchy
Now that you have defined a naming convention, you should also identify the branches’ hierarchy. You should identify at least two (or tree) branches:
- Main: contains code deployed and available online to final users
- Testing (staging): contains code deployed to the testing environment (pre-release)
- Develop:includes the latest version of the codebase available as starting point to the developer.
Suppose to have to collaborate with another ten people for the implementation of testing N features of an MVP (which needs to be released with all the N features requested). Each developer will create a new branch (checkout) from develop, implement their functionality, and create a merge request to merge the changes on developing.
Once the requirements are satisfied, develop is merged with staging (testing), and the artefacts procured by this merge, is the product given to the testing team.
Once all the bug fixes are closed, and the testing team approves the chances, you merge staging with the master and deploy to final real users the artefact produced by the master branch. The master branch so will contain the actual alpha (stable) versions of your product.
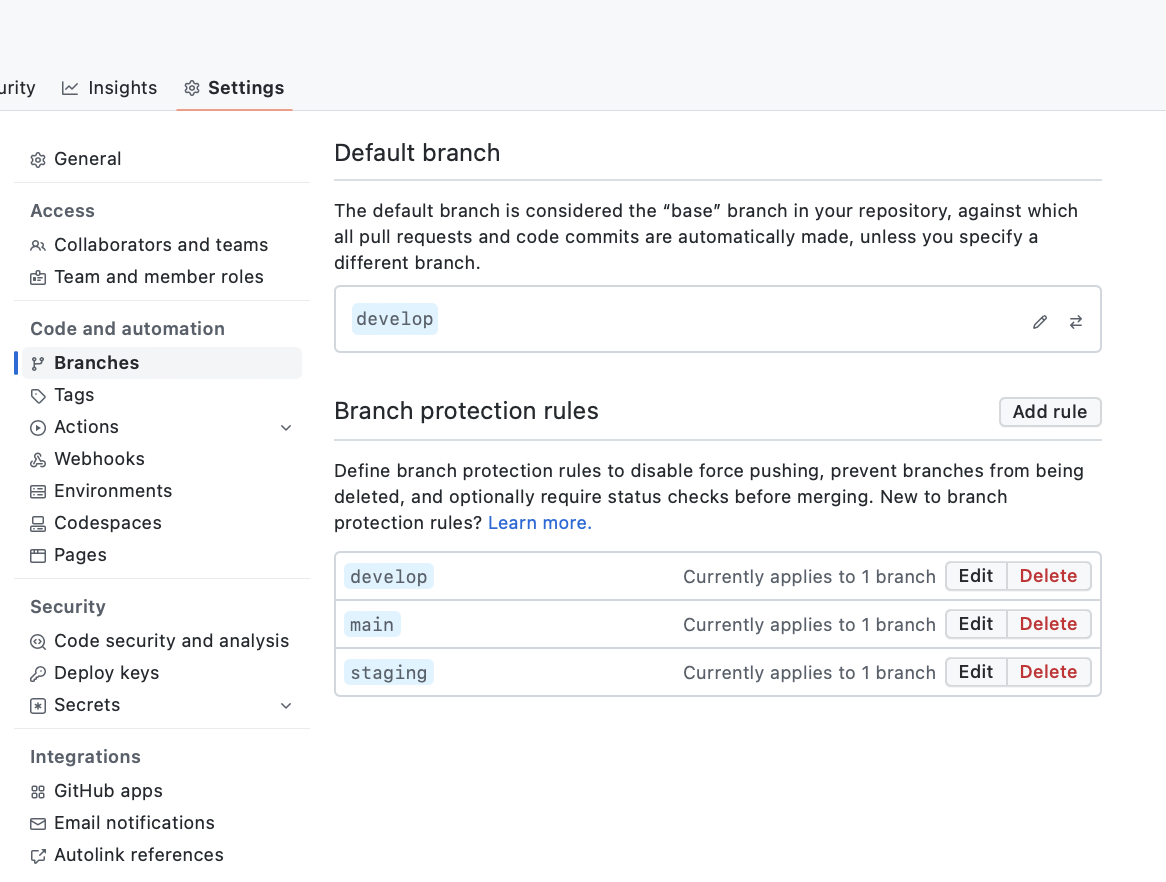
Branches protection rules
Now, we have talked about naming convention and hierarchy. Is now time to avoid common errors by configuring:
- Default branch: branch of the repository given to the user when the repository is loaded (on browsers) or cloned.
- Branch configurations rules, which allow defining:
- Push limits: (allows the introduction of new code just via merge request).
- The minimumnumber of reviews:State at least N people need to approve an MR before merging it.
- Require status checks to pass before merging: a force that all pipelines are successful prior to human approval before merging.
- Include administrators: Enforce all configured restrictions above for administrators.
Branch security rules configuration pages (Github.com)Dependencies Analysis
If you are using GitHub, you can use dependabot to daily, weekly or monthly scan your project’s dependencies and get automated Merge Requests in case of updates are needed.
Briefly, dependable scan your dependencies against a public database with known vulnerabilities and signalled vulnerable version currently adopted within your project.
In case of organization or private repositories, you can enable dependanbot alerts for new repository, and grant access to private ones, from the settings page of the organization profile.
Enable dependanbot and grant access to private repositoriesView the dependabot documentation
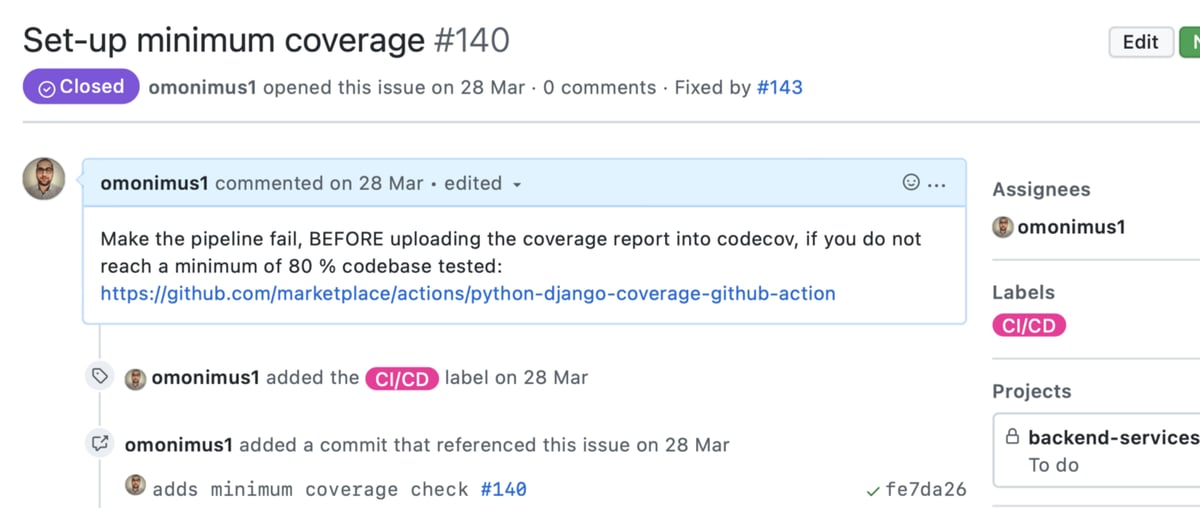
Testing coverage analysis & minimum coverage policy
Test your code, automate testing to avoid regression and know at any time:
- What is currently covered by automated testing or not
- Current coverage percentage.
Products like codecov allow you to reach this goal, for free, with both private and public repositories.
Codecov graph of the GetBuzz backendBy creating a codecov.yml at the root of your project, you will be able to set a minimum code coverage percentage accepted.
Below 80% (as shown below), any PR will fail, until new unit, functionality, or end-to-end tests are added and pushed;
Minimum coverage configurationsCode quality checks
Linters allow analysing of the overall quality code, indicating naming convention errors, duplicated code, and not-used imports (which overall may have a minimum impact on product performances).
More about this topic will be discussed in the Continuous Integration pipelines paragraph.
Continuous Integrations pipelines
As Atlassian states: Continuous integration (CI) is the practice of automating the integration of code changes from multiple contributors into a single software project. It’s a primary DevOps best practice, allowing developers to frequently merge code changes into a central repository where builds and tests are then run. Automated tools are used to assert the new code’s correctness before integration.
In short: is a set of automatic actions and checks executed before or after a new event (merge requests or push) occurs.
From the point of view of continuous integration, the minimum you can do at each PR or push is:
- Verify overall code quality via litres (view basic example for Django application).
- Run the suites of tests and validate that these are successful. (view example for Django application).
- Upload and verify the current testing coverage percentage (view example for Django Application).
The Github action marketplace contains a set of ready-to-use pipeline directives to achieve your goals if you are using Github.
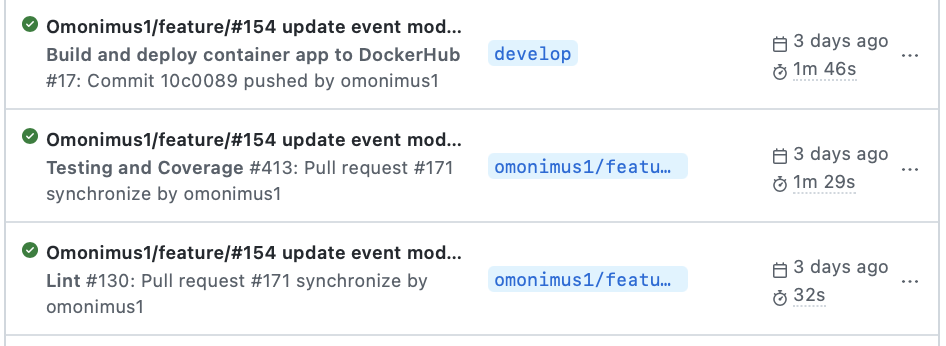
Github actions status historyMerge Request Review requests
All nice and great, and then?
All automatic tests are in place, git-flow is defined, and branch protection is applied. But, most importantly, it would be best if you determined how new merge requests are communicated.
Will you (as a reviewer) check daily in the morning and then in the afternoon before leaving your station? I would not do that.
I have created a dedicated slack channel where members can ask for a review, and attach a link to the review so that anyone can see the PR, verify it and give feedback as soon as possible, and decrease the time between PR creation and its merge.
Bug report strategy
Most of the developers complain that users are not able to report a bug and close the bug report justifying it as the impossibility to reproduce the bug.
The same developers, do nothing to avoid this. If you have a public form for evidence of a bug, ask within the form for any helpful information. In the case of a mobile application these could be:
- App version
- Phone model and version
- Possible screenshots/recording
Forinternal bug signalisation, you can define a default view that will be shown at each creation of a bug. To do so, on GitHub, you can define a bug template, which will be stored inside the .github/ISSUE_TEMPLATE folder.
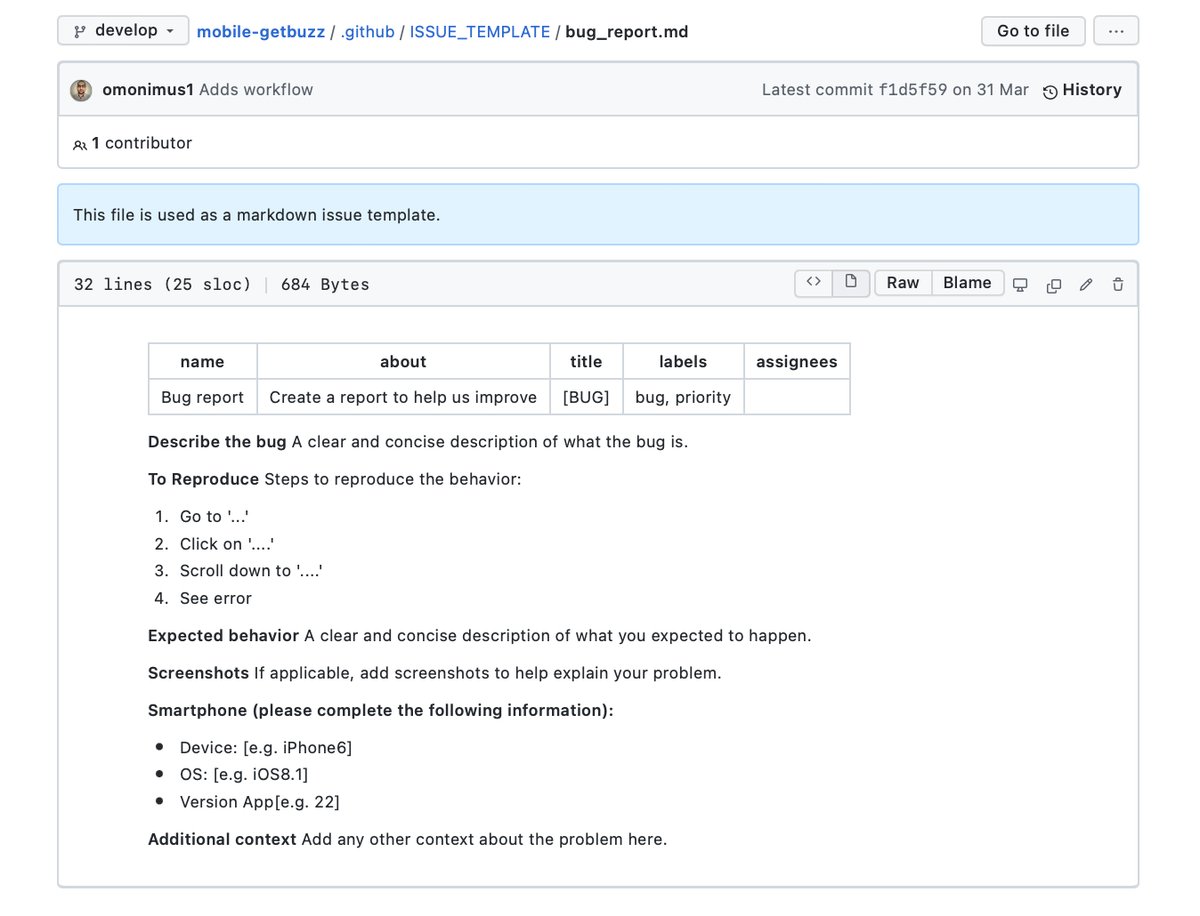
bug issue template+






